 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFew-Shot Classification & Segmentation Using Large Language Models Agent
Paper and Code
Nov 19, 2023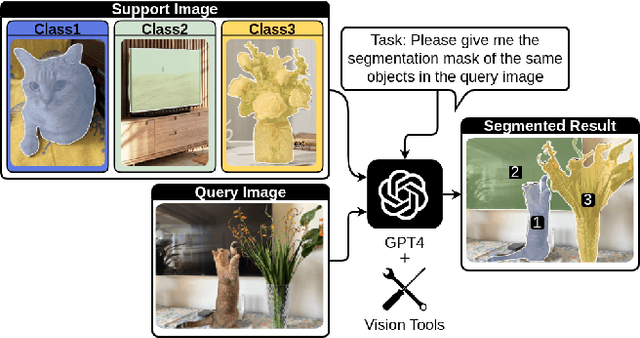
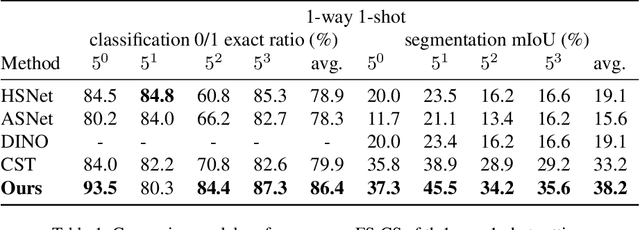
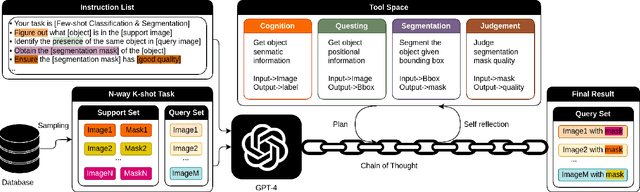

The task of few-shot image classification and segmentation (FS-CS) requires the classification and segmentation of target objects in a query image, given only a few examples of the target classes. We introduce a method that utilises large language models (LLM) as an agent to address the FS-CS problem in a training-free manner. By making the LLM the task planner and off-the-shelf vision models the tools, the proposed method is capable of classifying and segmenting target objects using only image-level labels. Specifically, chain-of-thought prompting and in-context learning guide the LLM to observe support images like human; vision models such as Segment Anything Model (SAM) and GPT-4Vision assist LLM understand spatial and semantic information at the same time. Ultimately, the LLM uses its summarizing and reasoning capabilities to classify and segment the query image. The proposed method's modular framework makes it easily extendable. Our approach achieves state-of-the-art performance on the Pascal-5i dataset.