 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA prototype system for handwritten sub-word recognition: Toward Arabic-manuscript transliteration
Nov 14, 2011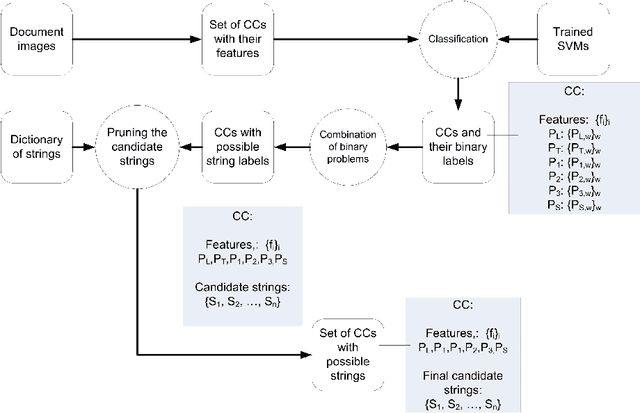


A prototype system for the transliteration of diacritics-less Arabic manuscripts at the sub-word or part of Arabic word (PAW) level is developed. The system is able to read sub-words of the input manuscript using a set of skeleton-based features. A variation of the system is also developed which reads archigraphemic Arabic manuscripts, which are dot-less, into archigraphemes transliteration. In order to reduce the complexity of the original highly multiclass problem of sub-word recognition, it is redefined into a set of binary descriptor classifiers. The outputs of trained binary classifiers are combined to generate the sequence of sub-word letters. SVMs are used to learn the binary classifiers. Two specific Arabic databases have been developed to train and test the system. One of them is a database of the Naskh style. The initial results are promising. The systems could be trained on other scripts found in Arabic manuscripts.