 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Spatial Mapping Algorithm with Applications in Deep Learning-Based Structure Classification
Feb 22, 2018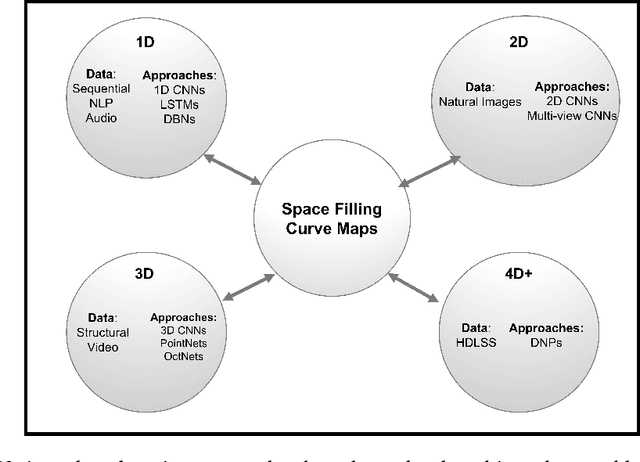

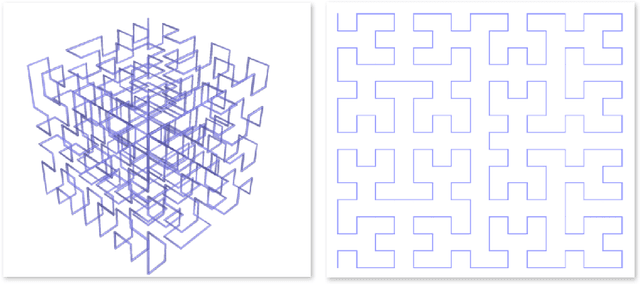
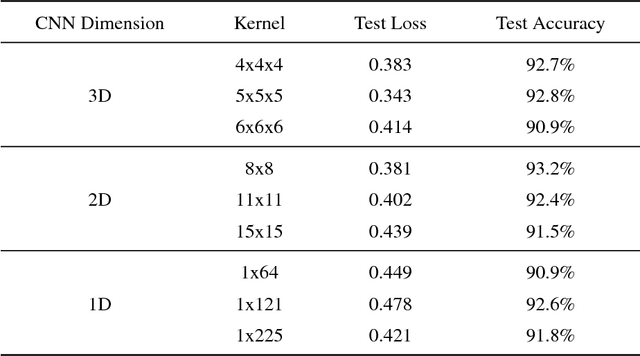
Convolutional Neural Network (CNN)-based machine learning systems have made breakthroughs in feature extraction and image recognition tasks in two dimensions (2D). Although there is significant ongoing work to apply CNN technology to domains involving complex 3D data, the success of such efforts has been constrained, in part, by limitations in data representation techniques. Most current approaches rely upon low-resolution 3D models, strategic limitation of scope in the 3D space, or the application of lossy projection techniques to allow for the use of 2D CNNs. To address this issue, we present a mapping algorithm that converts 3D structures to 2D and 1D data grids by mapping a traversal of a 3D space-filling curve to the traversal of corresponding 2D and 1D curves. We explore the performance of 2D and 1D CNNs trained on data encoded with our method versus comparable volumetric CNNs operating upon raw 3D data from a popular benchmarking dataset. Our experiments demonstrate that both 2D and 1D representations of 3D data generated via our method preserve a significant proportion of the 3D data's features in forms learnable by CNNs. Furthermore, we demonstrate that our method of encoding 3D data into lower-dimensional representations allows for decreased CNN training time cost, increased original 3D model rendering resolutions, and supports increased numbers of data channels when compared to purely volumetric approaches. This demonstration is accomplished in the context of a structural biology classification task wherein we train 3D, 2D, and 1D CNNs on examples of two homologous branches within the Ras protein family. The essential contribution of this paper is the introduction of a dimensionality-reduction method that may ease the application of powerful deep learning tools to domains characterized by complex structural data.
Identifying Subjective and Figurative Language in Online Dialogue
Aug 29, 2017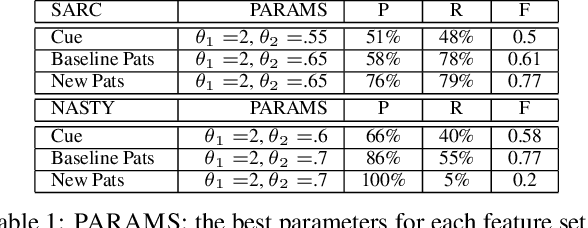
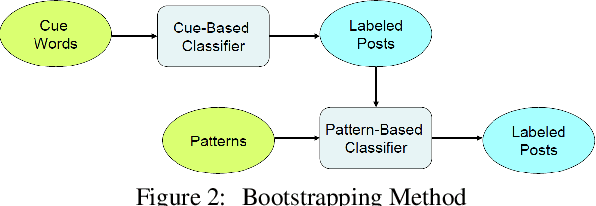
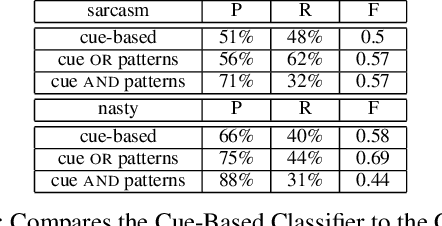
More and more of the information on the web is dialogic, from Facebook newsfeeds, to forum conversations, to comment threads on news articles. In contrast to traditional, monologic resources such as news, highly social dialogue is very frequent in social media. We aim to automatically identify sarcastic and nasty utterances in unannotated online dialogue, extending a bootstrapping method previously applied to the classification of monologic subjective sentences in Riloff and Weibe 2003. We have adapted the method to fit the sarcastic and nasty dialogic domain. Our method is as follows: 1) Explore methods for identifying sarcastic and nasty cue words and phrases in dialogues; 2) Use the learned cues to train a sarcastic (nasty) Cue-Based Classifier; 3) Learn general syntactic extraction patterns from the sarcastic (nasty) utterances and define fine-tuned sarcastic patterns to create a Pattern-Based Classifier; 4) Combine both Cue-Based and fine-tuned Pattern-Based Classifiers to maximize precision at the expense of recall and test on unannotated utterances.