 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeepXplain: XAI-Guided Autonomous Defense Against Multi-Stage APT Campaigns
Mar 22, 2026Advanced Persistent Threats (APTs) are stealthy, multi-stage attacks that require adaptive and timely defense. While deep reinforcement learning (DRL) enables autonomous cyber defense, its decisions are often opaque and difficult to trust in operational environments. This paper presents DeepXplain, an explainable DRL framework for stage-aware APT defense. Building on our prior DeepStage model, DeepXplain integrates provenance-based graph learning, temporal stage estimation, and a unified XAI pipeline that provides structural, temporal, and policy-level explanations. Unlike post-hoc methods, explanation signals are incorporated directly into policy optimization through evidence alignment and confidence-aware reward shaping. To the best of our knowledge, DeepXplain is the first framework to integrate explanation signals into reinforcement learning for APT defense. Experiments in a realistic enterprise testbed show improvements in stage-weighted F1-score (0.887 to 0.915) and success rate (84.7% to 89.6%), along with higher explanation confidence (0.86), improved fidelity (0.79), and more compact explanations (0.31). These results demonstrate enhanced effectiveness and trustworthiness of autonomous cyber defense.
DeepStage: Learning Autonomous Defense Policies Against Multi-Stage APT Campaigns
Mar 17, 2026This paper presents DeepStage, a deep reinforcement learning (DRL) framework for adaptive, stage-aware defense against Advanced Persistent Threats (APTs). The enterprise environment is modeled as a partially observable Markov decision process (POMDP), where host provenance and network telemetry are fused into unified provenance graphs. Building on our prior work, StageFinder, a graph neural encoder and an LSTM-based stage estimator infer probabilistic attacker stages aligned with the MITRE ATT&CK framework. These stage beliefs, combined with graph embeddings, guide a hierarchical Proximal Policy Optimization (PPO) agent that selects defense actions across monitoring, access control, containment, and remediation. Evaluated in a realistic enterprise testbed using CALDERA-driven APT playbooks, DeepStage achieves a stage-weighted F1-score of 0.89, outperforming a risk-aware DRL baseline by 21.9%. The results demonstrate effective stage-aware and cost-efficient autonomous cyber defense.
Destination-aware Adaptive Traffic Flow Rule Aggregation in Software-Defined Networks
Sep 07, 2019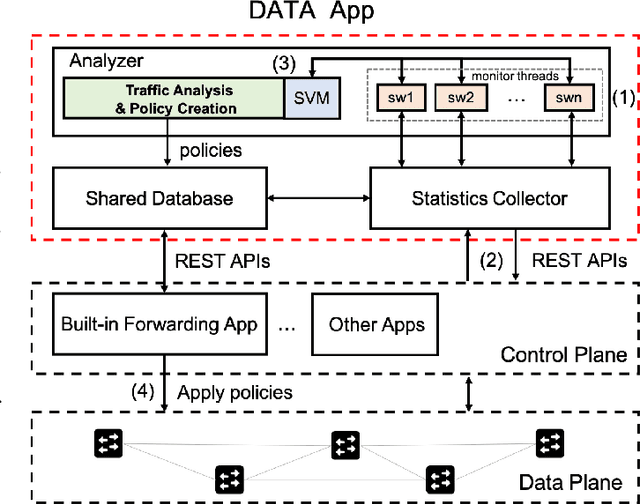
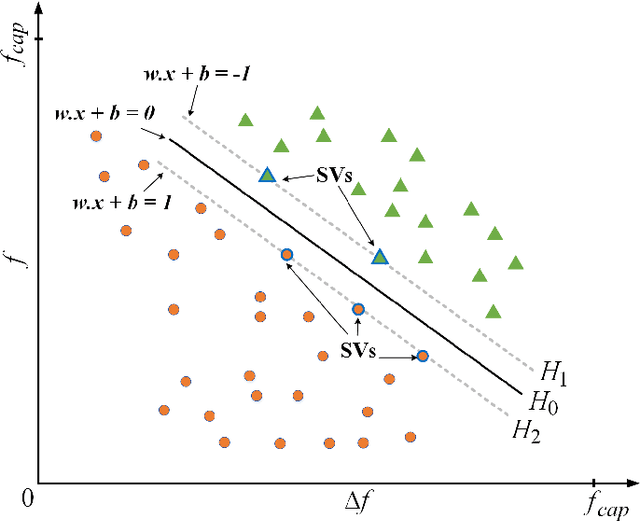
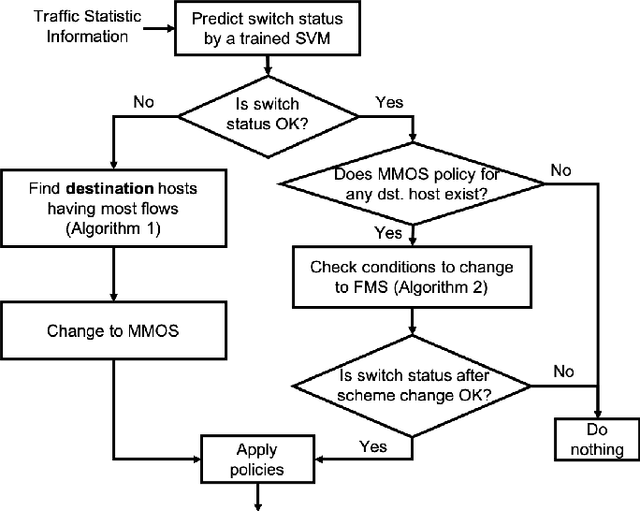
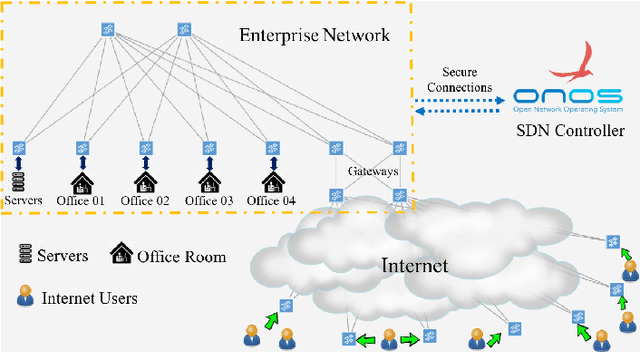
In this paper, we propose a destination-aware adaptive traffic flow rule aggregation (DATA) mechanism for facilitating traffic flow monitoring in SDN-based networks. This method adapts the number of flow table entries in SDN switches according to the level of detail of traffic flow information that other mechanisms (e.g. for traffic engineering, traffic monitoring, intrusion detection) require. It also prevents performance degradation of the SDN switches by keeping the number of flow table entries well below a critical level. This level is not preset as a hard threshold but learned during operation by using a machine-learning based algorithm. The DATA method is implemented within a RESTful application (DATA App) which monitors and analyzes the ongoing network traffic and provides instructions to the SDN controller to adapt the traffic flow matching strategies accordingly. A thorough performance evaluation of DATA is conducted in an SDN emulation environment. The results show that---compared to the default behavior of common SDN controllers---the proposed DATA approach yields significant SDN switch performance improvements while still providing detailed traffic flow information on demand.
Q-DATA: Enhanced Traffic Flow Monitoring in Software-Defined Networks applying Q-learning
Sep 04, 2019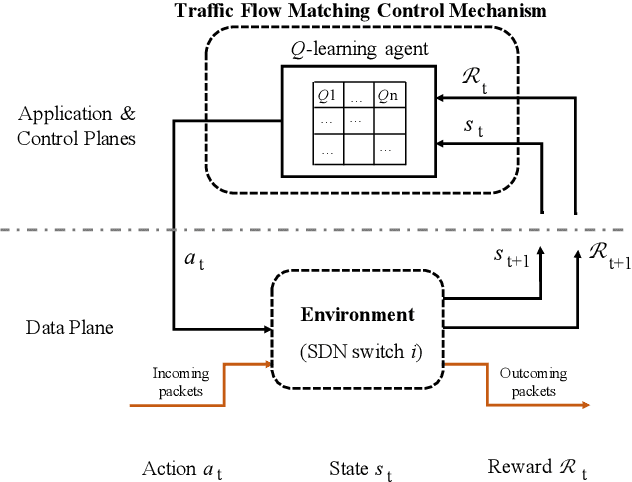

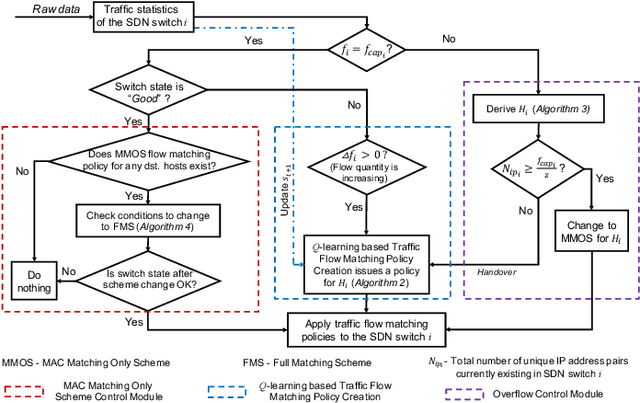
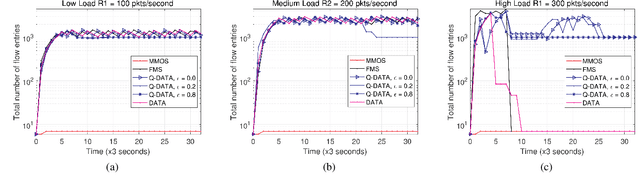
Software-Defined Networking (SDN) introduces a centralized network control and management by separating the data plane from the control plane which facilitates traffic flow monitoring, security analysis and policy formulation. However, it is challenging to choose a proper degree of traffic flow handling granularity while proactively protecting forwarding devices from getting overloaded. In this paper, we propose a novel traffic flow matching control framework called Q-DATA that applies reinforcement learning in order to enhance the traffic flow monitoring performance in SDN based networks and prevent traffic forwarding performance degradation. We first describe and analyse an SDN-based traffic flow matching control system that applies a reinforcement learning approach based on Q-learning algorithm in order to maximize the traffic flow granularity. It also considers the forwarding performance status of the SDN switches derived from a Support Vector Machine based algorithm. Next, we outline the Q-DATA framework that incorporates the optimal traffic flow matching policy derived from the traffic flow matching control system to efficiently provide the most detailed traffic flow information that other mechanisms require. Our novel approach is realized as a REST SDN application and evaluated in an SDN environment. Through comprehensive experiments, the results show that---compared to the default behavior of common SDN controllers and to our previous DATA mechanism---the new Q-DATA framework yields a remarkable improvement in terms of traffic forwarding performance degradation protection of SDN switches while still providing the most detailed traffic flow information on demand.
Q-MIND: Defeating Stealthy DoS Attacks in SDN with a Machine-learning based Defense Framework
Sep 03, 2019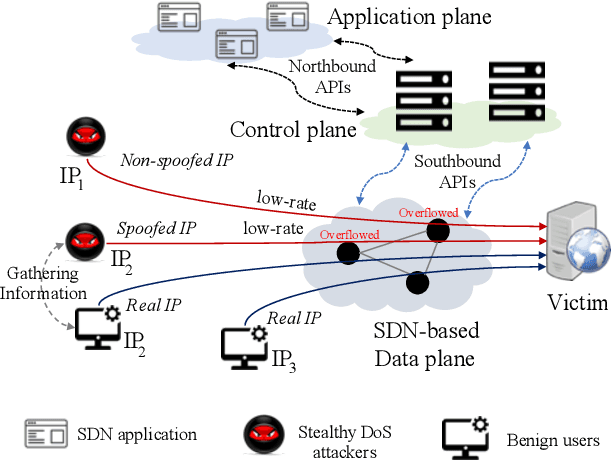
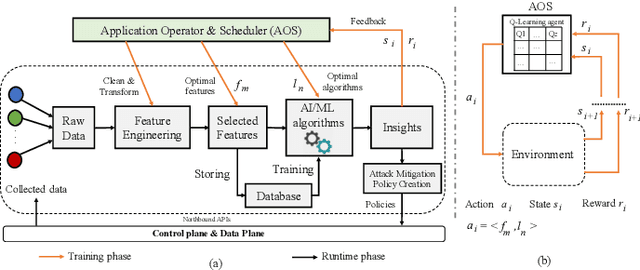
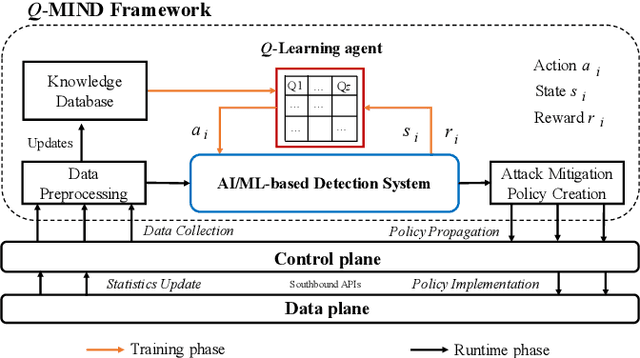
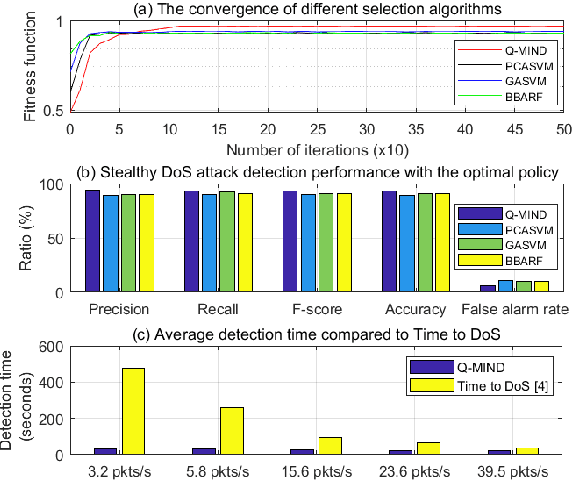
Software Defined Networking (SDN) enables flexible and scalable network control and management. However, it also introduces new vulnerabilities that can be exploited by attackers. In particular, low-rate and slow or stealthy Denial-of-Service (DoS) attacks are recently attracting attention from researchers because of their detection challenges. In this paper, we propose a novel machine learning based defense framework named Q-MIND, to effectively detect and mitigate stealthy DoS attacks in SDN-based networks. We first analyze the adversary model of stealthy DoS attacks, the related vulnerabilities in SDN-based networks and the key characteristics of stealthy DoS attacks. Next, we describe and analyze an anomaly detection system that uses a Reinforcement Learning-based approach based on Q-Learning in order to maximize its detection performance. Finally, we outline the complete Q-MIND defense framework that incorporates the optimal policy derived from the Q-Learning agent to efficiently defeat stealthy DoS attacks in SDN-based networks. An extensive comparison of the Q-MIND framework and currently existing methods shows that significant improvements in attack detection and mitigation performance are obtained by Q-MIND.