 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNonnegative Matrix Factorization to understand Spatio-Temporal Traffic Pattern Variations during COVID-19: A Case Study
Nov 05, 2021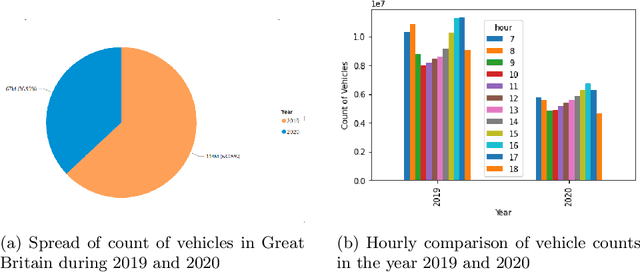
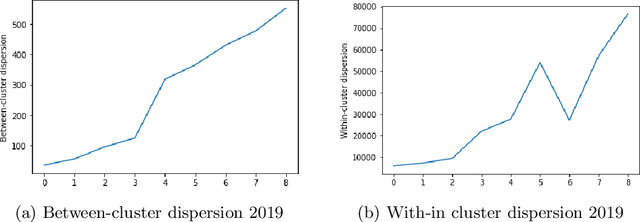
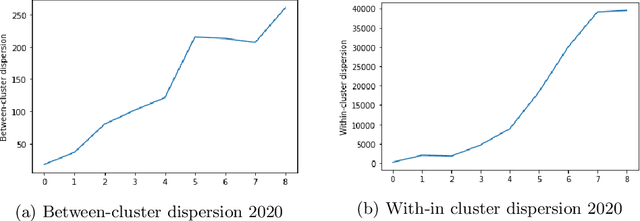
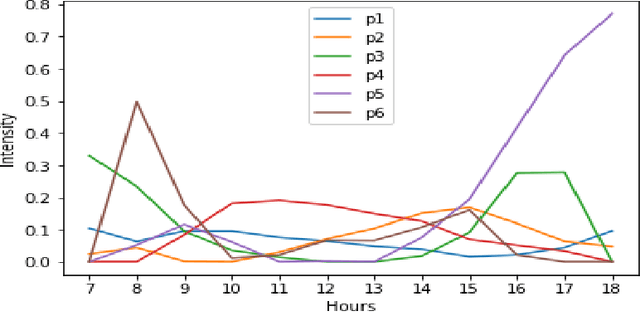
Due to the rapid developments in Intelligent Transportation System (ITS) and increasing trend in the number of vehicles on road, abundant of road traffic data is generated and available. Understanding spatio-temporal traffic patterns from this data is crucial and has been effectively helping in traffic plannings, road constructions, etc. However, understanding traffic patterns during COVID-19 pandemic is quite challenging and important as there is a huge difference in-terms of people's and vehicle's travel behavioural patterns. In this paper, a case study is conducted to understand the variations in spatio-temporal traffic patterns during COVID-19. We apply nonnegative matrix factorization (NMF) to elicit patterns. The NMF model outputs are analysed based on the spatio-temporal pattern behaviours observed during the year 2019 and 2020, which is before pandemic and during pandemic situations respectively, in Great Britain. The outputs of the analysed spatio-temporal traffic pattern variation behaviours will be useful in the fields of traffic management in Intelligent Transportation System and management in various stages of pandemic or unavoidable scenarios in-relation to road traffic.
A Semi-automatic Data Extraction System for Heterogeneous Data Sources: A Case Study from Cotton Industry
Nov 05, 2021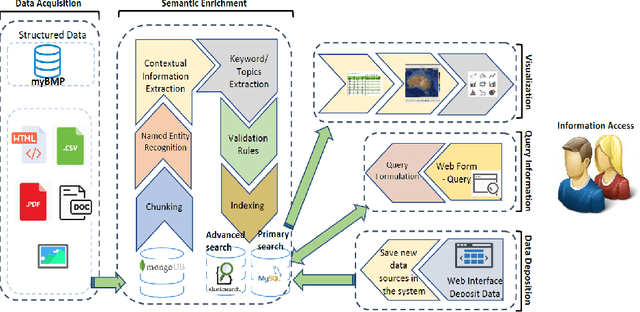
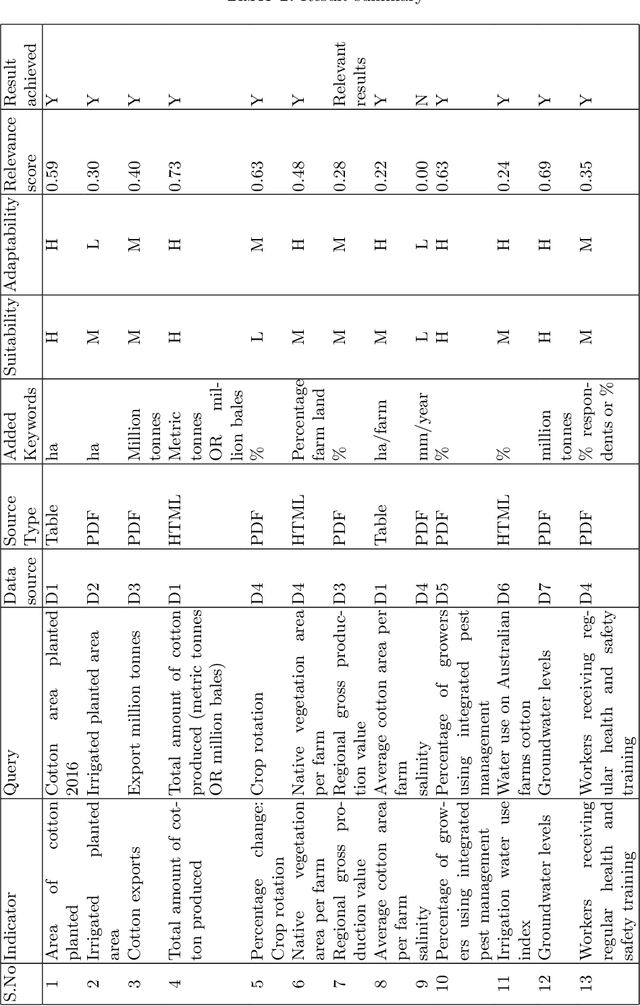

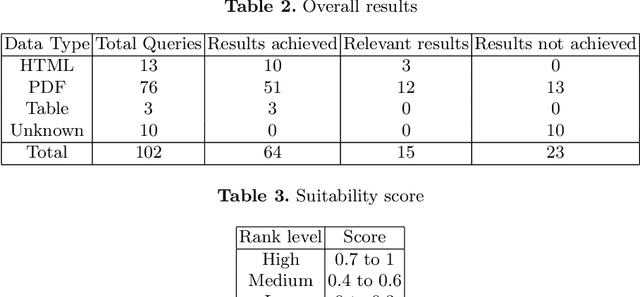
With the recent developments in digitisation, there are increasing number of documents available online. There are several information extraction tools that are available to extract information from digitised documents. However, identifying precise answers to a given query is often a challenging task especially if the data source where the relevant information resides is unknown. This situation becomes more complex when the data source is available in multiple formats such as PDF, table and html. In this paper, we propose a novel data extraction system to discover relevant and focused information from diverse unstructured data sources based on text mining approaches. We perform a qualitative analysis to evaluate the proposed system and its suitability and adaptability using cotton industry.
Investigation of Topic Modelling Methods for Understanding the Reports of the Mining Projects in Queensland
Nov 05, 2021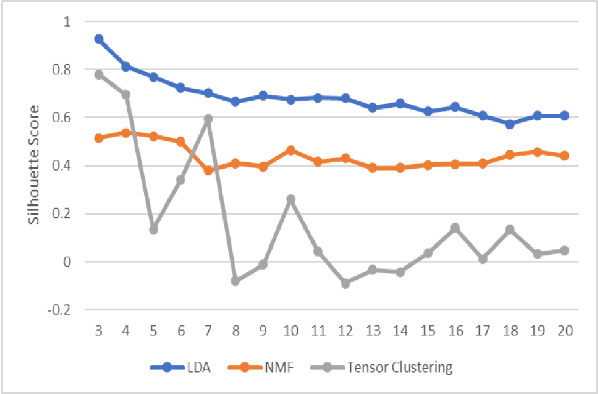
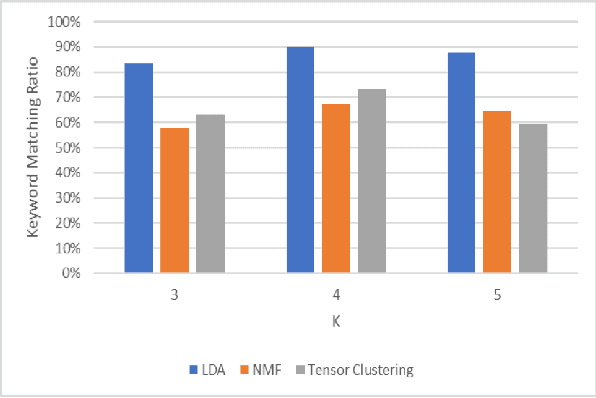
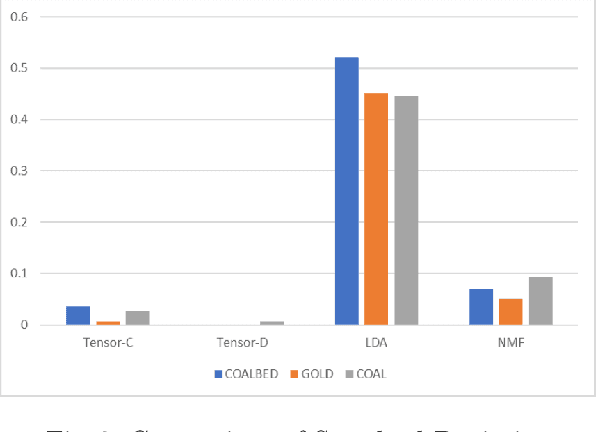
In the mining industry, many reports are generated in the project management process. These past documents are a great resource of knowledge for future success. However, it would be a tedious and challenging task to retrieve the necessary information if the documents are unorganized and unstructured. Document clustering is a powerful approach to cope with the problem, and many methods have been introduced in past studies. Nonetheless, there is no silver bullet that can perform the best for any types of documents. Thus, exploratory studies are required to apply the clustering methods for new datasets. In this study, we will investigate multiple topic modelling (TM) methods. The objectives are finding the appropriate approach for the mining project reports using the dataset of the Geological Survey of Queensland, Department of Resources, Queensland Government, and understanding the contents to get the idea of how to organise them. Three TM methods, Latent Dirichlet Allocation (LDA), Nonnegative Matrix Factorization (NMF), and Nonnegative Tensor Factorization (NTF) are compared statistically and qualitatively. After the evaluation, we conclude that the LDA performs the best for the dataset; however, the possibility remains that the other methods could be adopted with some improvements.
Understanding the Spatio-temporal Topic Dynamics of Covid-19 using Nonnegative Tensor Factorization: A Case Study
Sep 19, 2020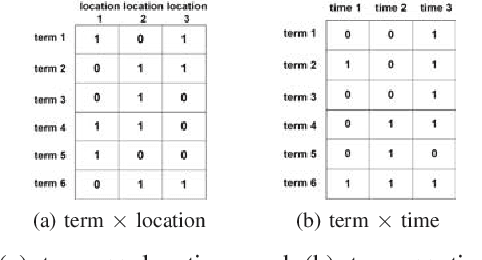
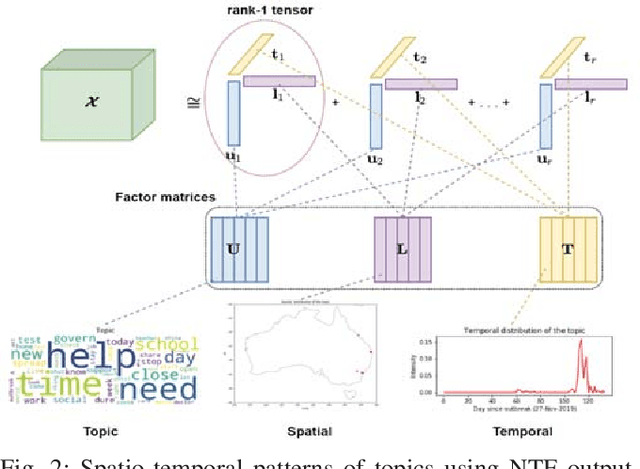
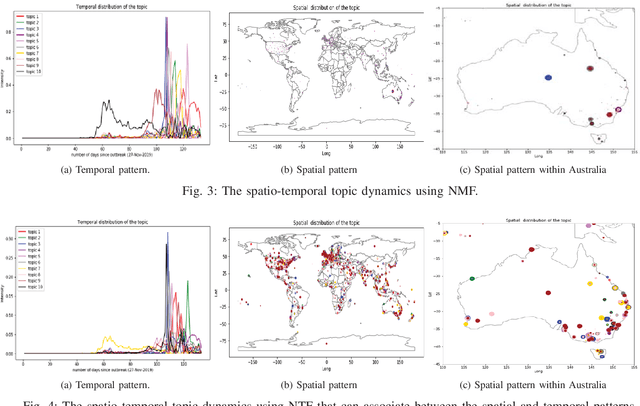
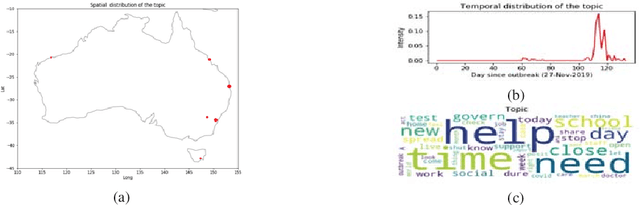
Social media platforms facilitate mankind a data-driven world by enabling billions of people to share their thoughts and activities ubiquitously. This huge collection of data, if analysed properly, can provide useful insights into people's behavior. More than ever, now is a crucial time under the Covid-19 pandemic to understand people's online behaviors detailing what topics are being discussed, and where (space) and when (time) they are discussed. Given the high complexity and poor quality of the huge social media data, an effective spatio-temporal topic detection method is needed. This paper proposes a tensor-based representation of social media data and Non-negative Tensor Factorization (NTF) to identify the topics discussed in social media data along with the spatio-temporal topic dynamics. A case study on Covid-19 related tweets from the Australia Twittersphere is presented to identify and visualize spatio-temporal topic dynamics on Covid-19
Topic, Sentiment and Impact Analysis: COVID19 Information Seeking on Social Media
Aug 28, 2020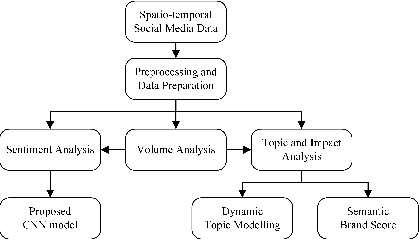
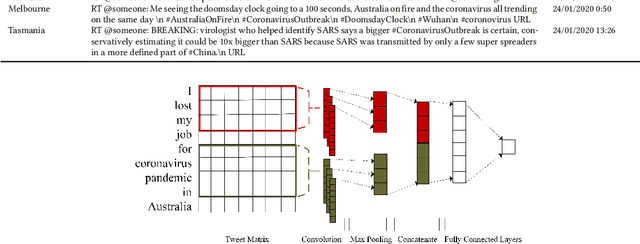
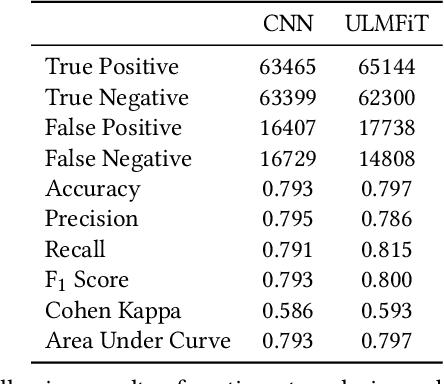

When people notice something unusual, they discuss it on social media. They leave traces of their emotions via text expressions. A systematic collection, analysis, and interpretation of social media data across time and space can give insights on local outbreaks, mental health, and social issues. Such timely insights can help in developing strategies and resources with an appropriate and efficient response. This study analysed a large Spatio-temporal tweet dataset of the Australian sphere related to COVID19. The methodology included a volume analysis, dynamic topic modelling, sentiment detection, and semantic brand score to obtain an insight on the COVID19 pandemic outbreak and public discussion in different states and cities of Australia over time. The obtained insights are compared with independently observed phenomena such as government reported instances.
Efficient Nonnegative Tensor Factorization via Saturating Coordinate Descent
Mar 07, 2020
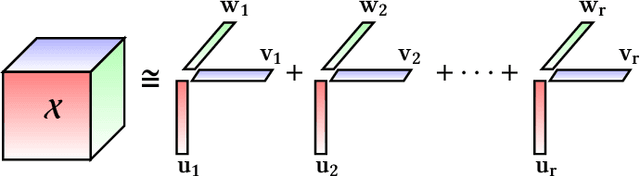

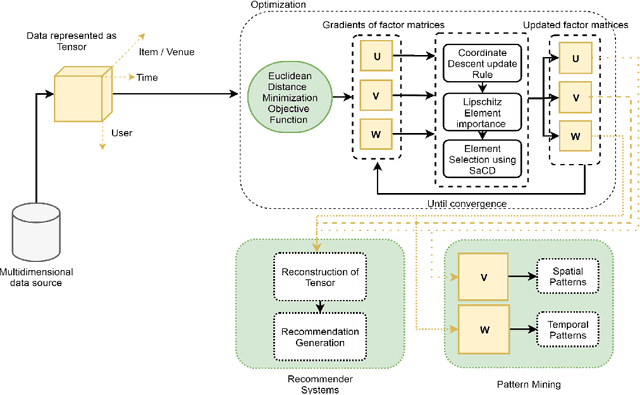
With the advancements in computing technology and web-based applications, data is increasingly generated in multi-dimensional form. This data is usually sparse due to the presence of a large number of users and fewer user interactions. To deal with this, the Nonnegative Tensor Factorization (NTF) based methods have been widely used. However existing factorization algorithms are not suitable to process in all three conditions of size, density, and rank of the tensor. Consequently, their applicability becomes limited. In this paper, we propose a novel fast and efficient NTF algorithm using the element selection approach. We calculate the element importance using Lipschitz continuity and propose a saturation point based element selection method that chooses a set of elements column-wise for updating to solve the optimization problem. Empirical analysis reveals that the proposed algorithm is scalable in terms of tensor size, density, and rank in comparison to the relevant state-of-the-art algorithms.
Columnwise Element Selection for Computationally Efficient Nonnegative Coupled Matrix Tensor Factorization
Mar 07, 2020
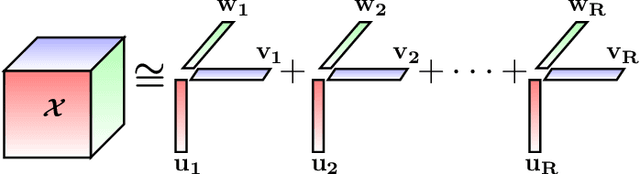
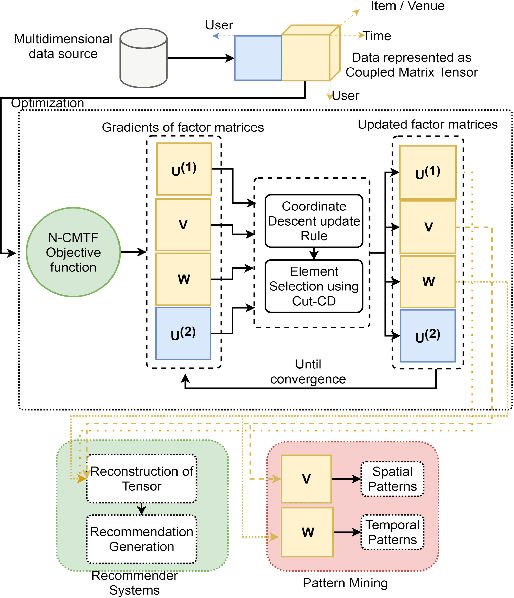
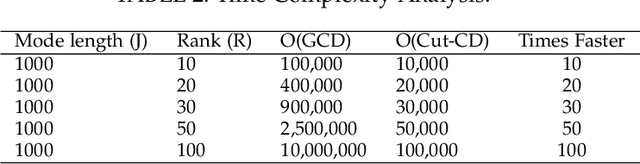
Coupled Matrix Tensor Factorization (CMTF) facilitates the integration and analysis of multiple data sources and helps discover meaningful information. Nonnegative CMTF (N-CMTF) has been employed in many applications for identifying latent patterns, prediction, and recommendation. However, due to the added complexity with coupling between tensor and matrix data, existing N-CMTF algorithms exhibit poor computation efficiency. In this paper, a computationally efficient N-CMTF factorization algorithm is presented based on the column-wise element selection, preventing frequent gradient updates. Theoretical and empirical analyses show that the proposed N-CMTF factorization algorithm is not only more accurate but also more computationally efficient than existing algorithms in approximating the tensor as well as in identifying the underlying nature of factors.