 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the Wasserstein Geodesic Principal Component Analysis of probability measures
Jun 04, 2025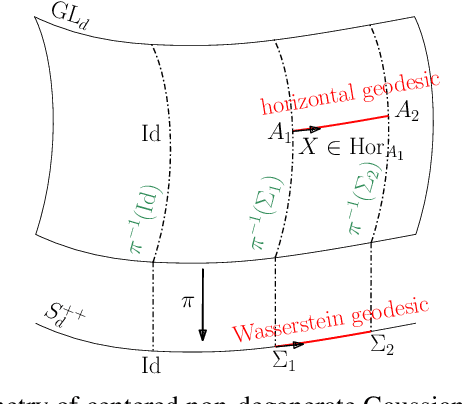

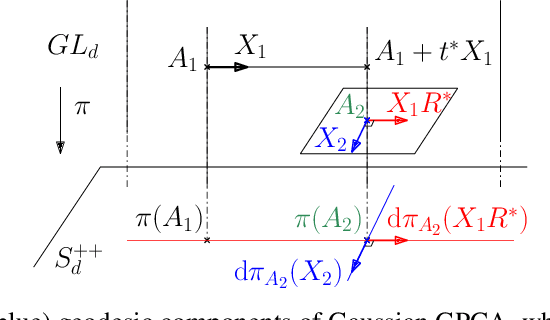
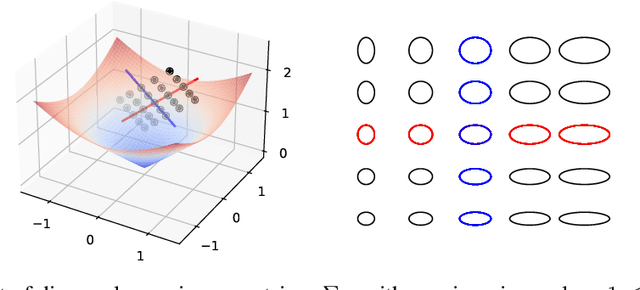
This paper focuses on Geodesic Principal Component Analysis (GPCA) on a collection of probability distributions using the Otto-Wasserstein geometry. The goal is to identify geodesic curves in the space of probability measures that best capture the modes of variation of the underlying dataset. We first address the case of a collection of Gaussian distributions, and show how to lift the computations in the space of invertible linear maps. For the more general setting of absolutely continuous probability measures, we leverage a novel approach to parameterizing geodesics in Wasserstein space with neural networks. Finally, we compare to classical tangent PCA through various examples and provide illustrations on real-world datasets.
A case study : Influence of Dimension Reduction on regression trees-based Algorithms -Predicting Aeronautics Loads of a Derivative Aircraft
Nov 16, 2018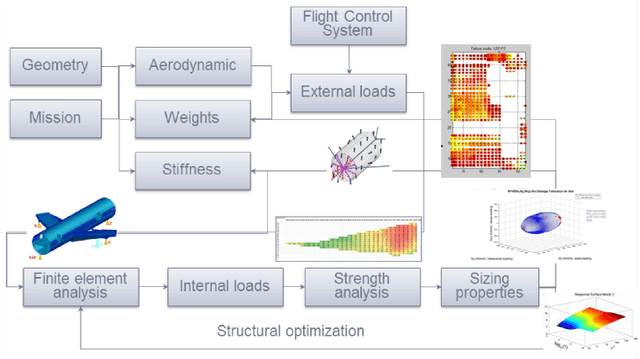

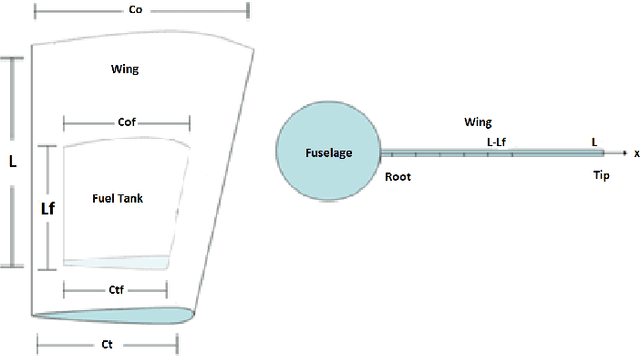

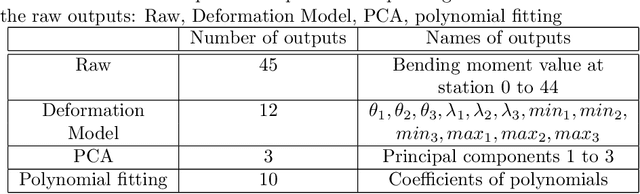
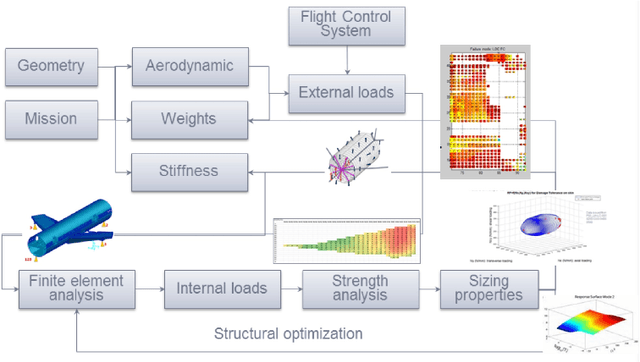
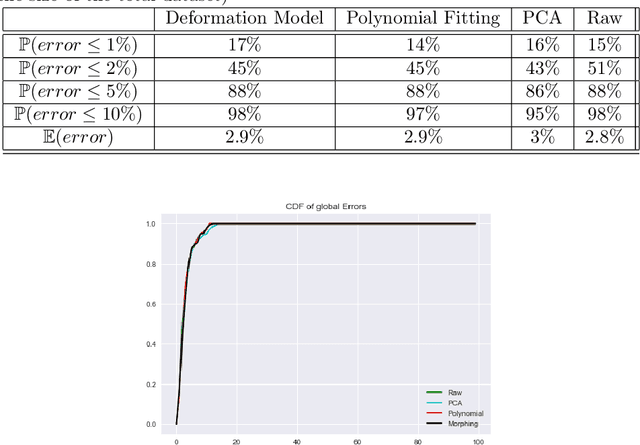
In aircraft industry, market needs evolve quickly in a high competitiveness context. This requires adapting a given aircraft model in minimum time considering for example an increase of range or the number of passengers (cf A330 NEO family). The computation of loads and stress to resize the airframe is on the critical path of this aircraft variant definition: this is a consuming and costly process, one of the reason being the high dimen-sionality and the large amount of data. This is why Airbus has invested since a couple of years in Big Data approaches (statistic methods up to machine learning) to improve the speed, the data value extraction and the responsiveness of this process. This paper presents recent advances in this work made in cooperation between Airbus, ENAC and Institut de Math{\'e}-matiques de Toulouse in the framework of a proof of value sprint project. It compares the influence of three dimensional reduction techniques (PCA, polynomial fitting, combined) on the extrapolation capabilities of Regression Trees based algorithms for loads prediction. It shows that AdaBoost with Random Forest offers promising results in average in terms of accuracy and computational time to estimate loads on which a PCA is applied only on the outputs.
Semi Parametric Estimations of rotating and scaling parameters for aeronautic loads
Sep 24, 2018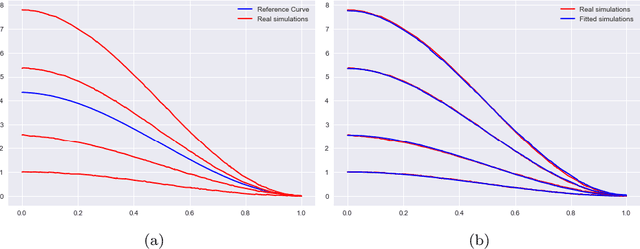
In this paper, we perform registration of noisy curves. We provide an appropriate model in estimating the rotation and scaling parameters to adjust a set of curves through a M-estimation procedure. We prove the consistency and the asymptotic normality of our estimators. Numerical simulation and a real life aeronautic example are given to illustrate our methodology.
Classification with the nearest neighbor rule in general finite dimensional spaces: necessary and sufficient conditions
Nov 05, 2014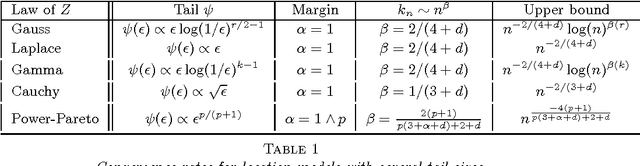
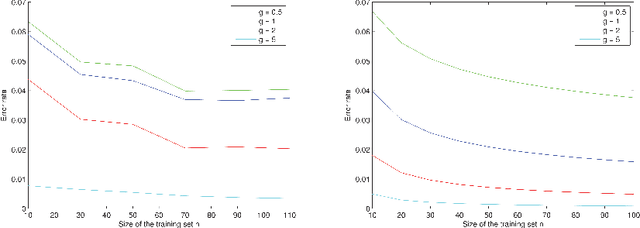
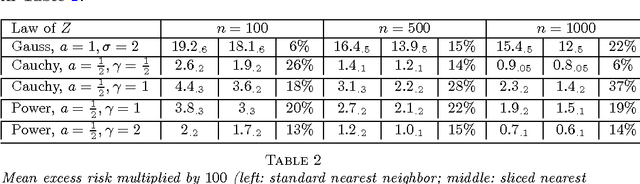
Given an $n$-sample of random vectors $(X_i,Y_i)_{1 \leq i \leq n}$ whose joint law is unknown, the long-standing problem of supervised classification aims to \textit{optimally} predict the label $Y$ of a given a new observation $X$. In this context, the nearest neighbor rule is a popular flexible and intuitive method in non-parametric situations. Even if this algorithm is commonly used in the machine learning and statistics communities, less is known about its prediction ability in general finite dimensional spaces, especially when the support of the density of the observations is $\mathbb{R}^d$. This paper is devoted to the study of the statistical properties of the nearest neighbor rule in various situations. In particular, attention is paid to the marginal law of $X$, as well as the smoothness and margin properties of the \textit{regression function} $\eta(X) = \mathbb{E}[Y | X]$. We identify two necessary and sufficient conditions to obtain uniform consistency rates of classification and to derive sharp estimates in the case of the nearest neighbor rule. Some numerical experiments are proposed at the end of the paper to help illustrate the discussion.