 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReinforcement Learning from LLM Feedback to Counteract Goal Misgeneralization
Jan 14, 2024We introduce a method to address goal misgeneralization in reinforcement learning (RL), leveraging Large Language Model (LLM) feedback during training. Goal misgeneralization, a type of robustness failure in RL occurs when an agent retains its capabilities out-of-distribution yet pursues a proxy rather than the intended one. Our approach utilizes LLMs to analyze an RL agent's policies during training and identify potential failure scenarios. The RL agent is then deployed in these scenarios, and a reward model is learnt through the LLM preferences and feedback. This LLM-informed reward model is used to further train the RL agent on the original dataset. We apply our method to a maze navigation task, and show marked improvements in goal generalization, especially in cases where true and proxy goals are somewhat distinguishable and behavioral biases are pronounced. This study demonstrates how the LLM, despite its lack of task proficiency, can efficiently supervise RL agents, providing scalable oversight and valuable insights for enhancing goal-directed learning in RL through the use of LLMs.
HySTER: A Hybrid Spatio-Temporal Event Reasoner
Jan 17, 2021
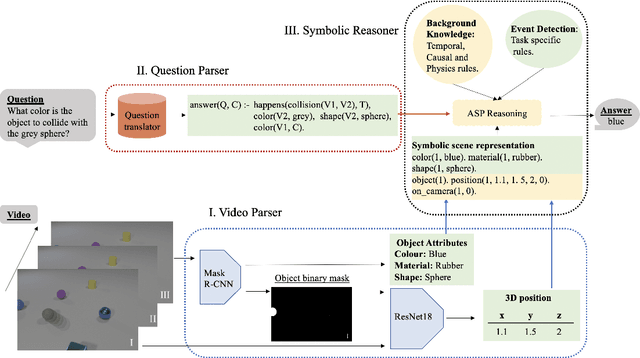

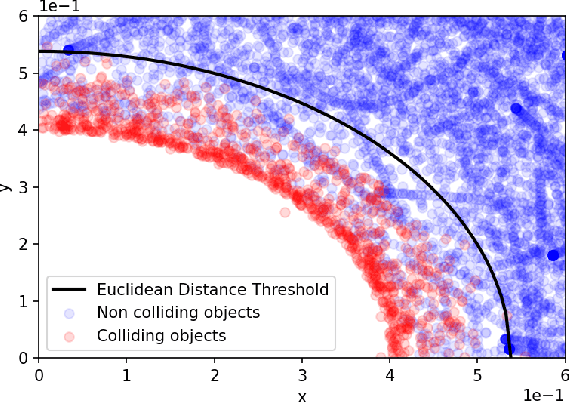
The task of Video Question Answering (VideoQA) consists in answering natural language questions about a video and serves as a proxy to evaluate the performance of a model in scene sequence understanding. Most methods designed for VideoQA up-to-date are end-to-end deep learning architectures which struggle at complex temporal and causal reasoning and provide limited transparency in reasoning steps. We present the HySTER: a Hybrid Spatio-Temporal Event Reasoner to reason over physical events in videos. Our model leverages the strength of deep learning methods to extract information from video frames with the reasoning capabilities and explainability of symbolic artificial intelligence in an answer set programming framework. We define a method based on general temporal, causal and physics rules which can be transferred across tasks. We apply our model to the CLEVRER dataset and demonstrate state-of-the-art results in question answering accuracy. This work sets the foundations for the incorporation of inductive logic programming in the field of VideoQA.