 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeArtificial Intelligence in Pediatric Echocardiography: Exploring Challenges, Opportunities, and Clinical Applications with Explainable AI and Federated Learning
Nov 15, 2024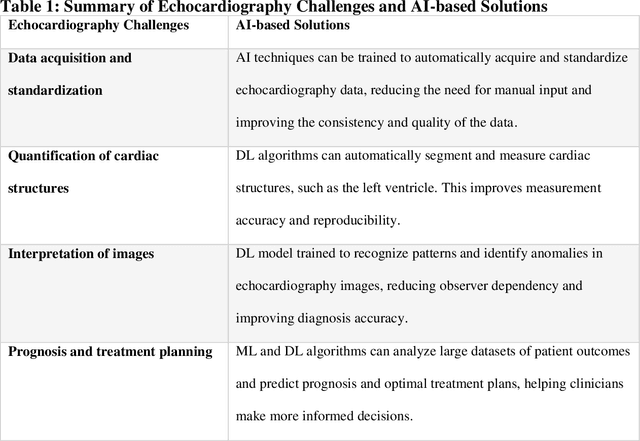
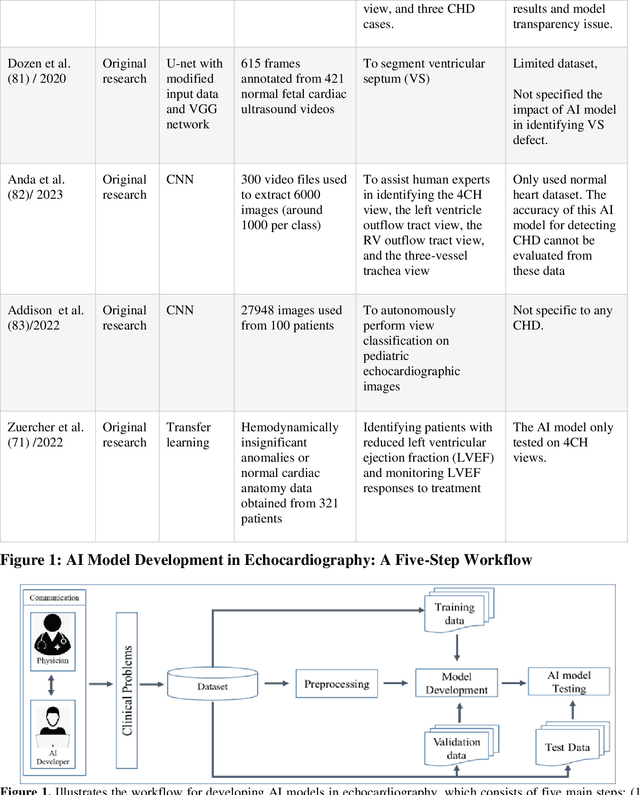


Pediatric heart diseases present a broad spectrum of congenital and acquired diseases. More complex congenital malformations require a differentiated and multimodal decision-making process, usually including echocardiography as a central imaging method. Artificial intelligence (AI) offers considerable promise for clinicians by facilitating automated interpretation of pediatric echocardiography data. However, adapting AI technologies for pediatric echocardiography analysis has challenges such as limited public data availability, data privacy, and AI model transparency. Recently, researchers have focused on disruptive technologies, such as federated learning (FL) and explainable AI (XAI), to improve automatic diagnostic and decision support workflows. This study offers a comprehensive overview of the limitations and opportunities of AI in pediatric echocardiography, emphasizing the synergistic workflow and role of XAI and FL, identifying research gaps, and exploring potential future developments. Additionally, three relevant clinical use cases demonstrate the functionality of XAI and FL with a focus on (i) view recognition, (ii) disease classification, (iii) segmentation of cardiac structures, and (iv) quantitative assessment of cardiac function.
MedDoc-Bot: A Chat Tool for Comparative Analysis of Large Language Models in the Context of the Pediatric Hypertension Guideline
May 06, 2024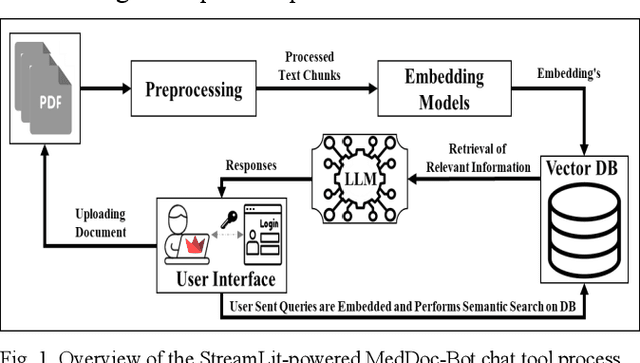
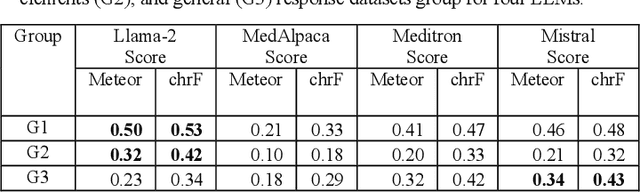
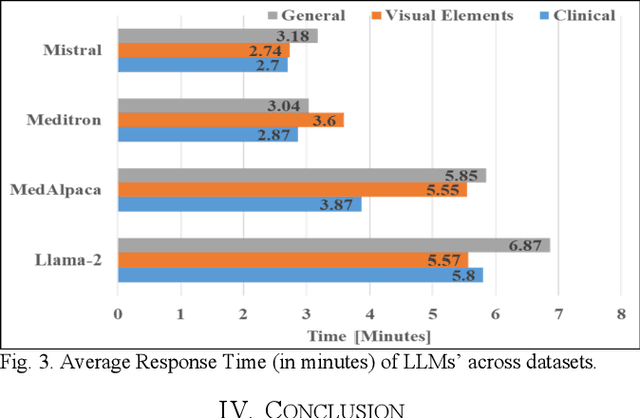
This research focuses on evaluating the non-commercial open-source large language models (LLMs) Meditron, MedAlpaca, Mistral, and Llama-2 for their efficacy in interpreting medical guidelines saved in PDF format. As a specific test scenario, we applied these models to the guidelines for hypertension in children and adolescents provided by the European Society of Cardiology (ESC). Leveraging Streamlit, a Python library, we developed a user-friendly medical document chatbot tool (MedDoc-Bot). This tool enables authorized users to upload PDF files and pose questions, generating interpretive responses from four locally stored LLMs. A pediatric expert provides a benchmark for evaluation by formulating questions and responses extracted from the ESC guidelines. The expert rates the model-generated responses based on their fidelity and relevance. Additionally, we evaluated the METEOR and chrF metric scores to assess the similarity of model responses to reference answers. Our study found that Llama-2 and Mistral performed well in metrics evaluation. However, Llama-2 was slower when dealing with text and tabular data. In our human evaluation, we observed that responses created by Mistral, Meditron, and Llama-2 exhibited reasonable fidelity and relevance. This study provides valuable insights into the strengths and limitations of LLMs for future developments in medical document interpretation. Open-Source Code: https://github.com/yaseen28/MedDoc-Bot