 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMultiple Pretext-Task for Self-Supervised Learning via Mixing Multiple Image Transformations
Dec 25, 2019


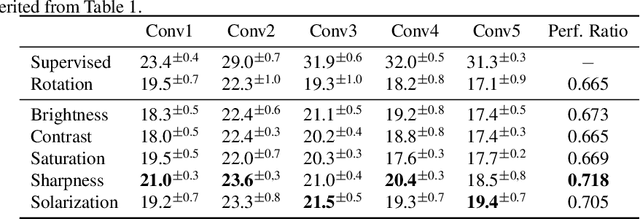
Self-supervised learning is one of the most promising approaches to learn representations capturing semantic features in images without any manual annotation cost. To learn useful representations, a self-supervised model solves a pretext-task, which is defined by data itself. Among a number of pretext-tasks, the rotation prediction task (Rotation) achieves better representations for solving various target tasks despite its simplicity of the implementation. However, we found that Rotation can fail to capture semantic features related to image textures and colors. To tackle this problem, we introduce a learning technique called multiple pretext-task for self-supervised learning (MP-SSL), which solves multiple pretext-task in addition to Rotation simultaneously. In order to capture features of textures and colors, we employ the transformations of image enhancements (e.g., sharpening and solarizing) as the additional pretext-tasks. MP-SSL efficiently trains a model by leveraging a Frank-Wolfe based multi-task training algorithm. Our experimental results show MP-SSL models outperform Rotation on multiple standard benchmarks and achieve state-of-the-art performance on Places-205.