 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConsistency between ordering and clustering methods for graphs
Aug 27, 2022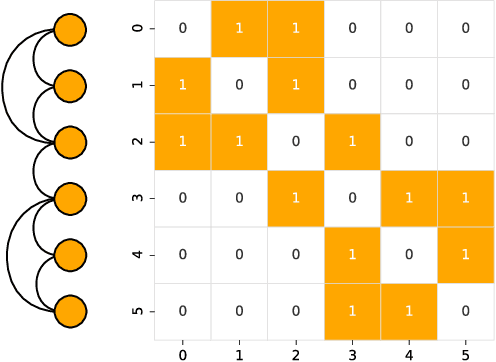
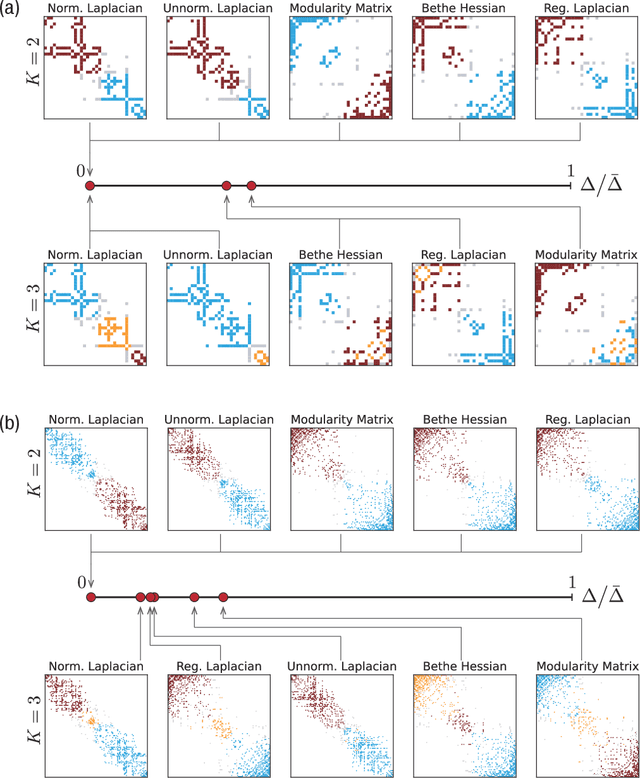
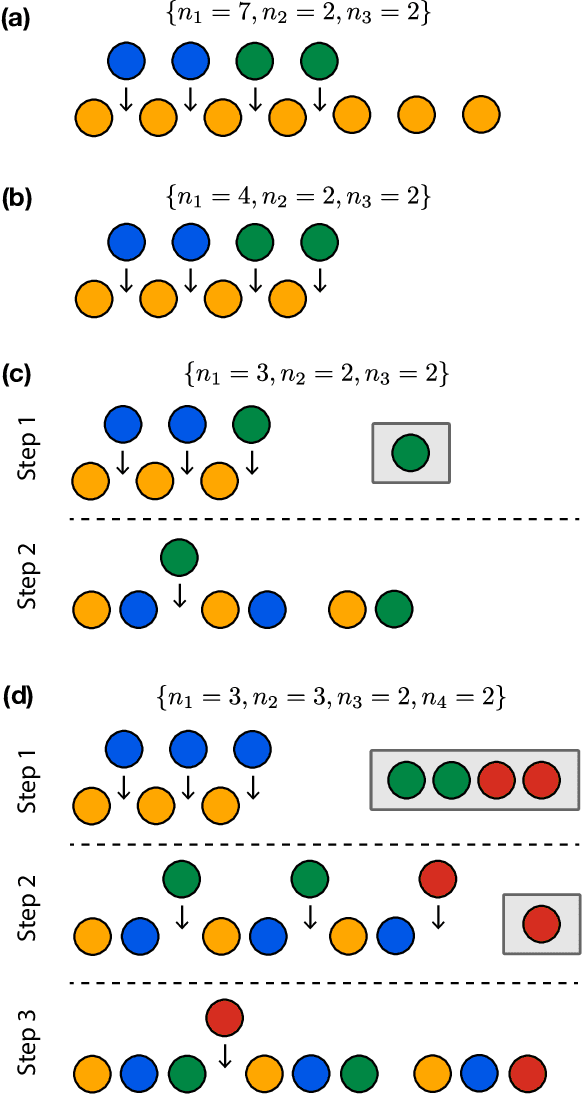

A relational dataset is often analyzed by optimally assigning a label to each element through clustering or ordering. While similar characterizations of a dataset would be achieved by both clustering and ordering methods, the former has been studied much more actively than the latter, particularly for the data represented as graphs. This study fills this gap by investigating methodological relationships between several clustering and ordering methods, focusing on spectral techniques. Furthermore, we evaluate the resulting performance of the clustering and ordering methods. To this end, we propose a measure called the label continuity error, which generically quantifies the degree of consistency between a sequence and partition for a set of elements. Based on synthetic and real-world datasets, we evaluate the extents to which an ordering method identifies a module structure and a clustering method identifies a banded structure.
Detecting multi-timescale consumption patterns from receipt data: A non-negative tensor factorization approach
Apr 28, 2020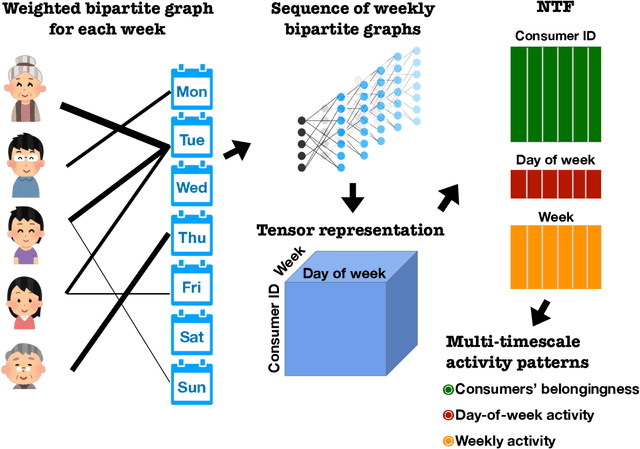
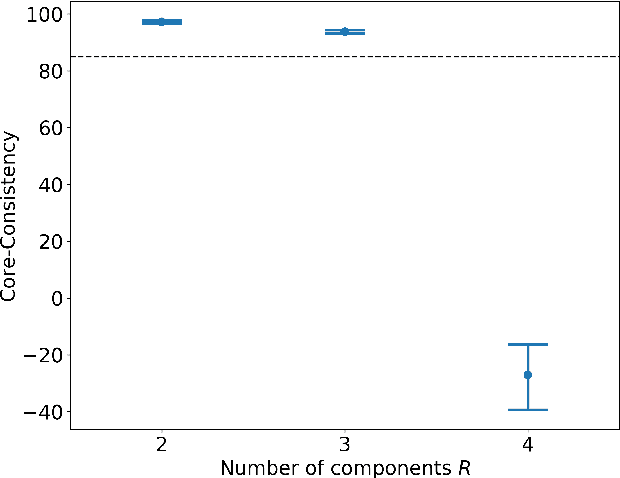
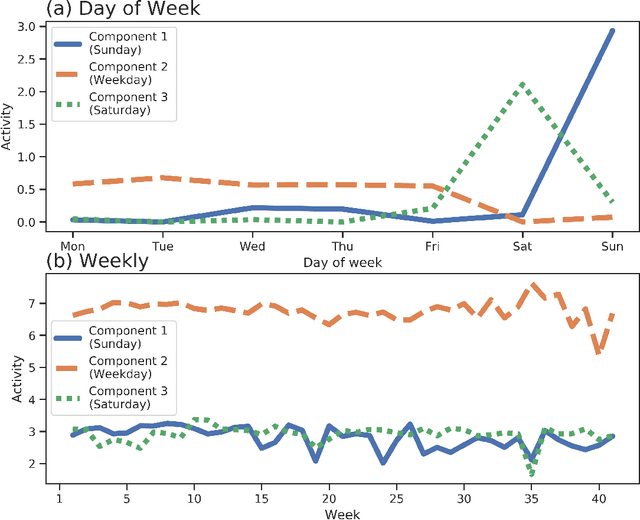

Understanding consumer behavior is an important task, not only for developing marketing strategies but also for the management of economic policies. Detecting consumption patterns, however, is a high-dimensional problem in which various factors that would affect consumers' behavior need to be considered, such as consumers' demographics, circadian rhythm, seasonal cycles, etc. Here, we develop a method to extract multi-timescale expenditure patterns of consumers from a large dataset of scanned receipts. We use a non-negative tensor factorization (NTF) to detect intra- and inter-week consumption patterns at one time. The proposed method allows us to characterize consumers based on their consumption patterns that are correlated over different timescales.