 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLeveraging Semantic Segmentation Masks with Embeddings for Fine-Grained Form Classification
May 23, 2024

Efficient categorization of historical documents is crucial for fields such as genealogy, legal research, and historical scholarship, where manual classification is impractical for large collections due to its labor-intensive and error-prone nature. To address this, we propose a representational learning strategy that integrates semantic segmentation and deep learning models -- ResNets, CLIP, the Document Image Transformer (DiT), and masked auto-encoders (MAE) -- to generate embeddings that capture document features without predefined labels. To the best of our knowledge, we are the first to evaluate embeddings on fine-grained, unsupervised form classification. To improve these embeddings, we propose to first employ semantic segmentation as a preprocessing step. We contribute two novel datasets -- French 19th-century and U.S. 1950 Census records -- to demonstrate our approach. Our results show the effectiveness of these various embedding techniques in distinguishing similar document types and indicate that applying semantic segmentation can greatly improve clustering and classification results. The census datasets are available at \href{https://github.com/tahlor/census_forms}{https://github.com/tahlor/census\_forms}.
DELINE8K: A Synthetic Data Pipeline for the Semantic Segmentation of Historical Documents
Apr 30, 2024Document semantic segmentation is a promising avenue that can facilitate document analysis tasks, including optical character recognition (OCR), form classification, and document editing. Although several synthetic datasets have been developed to distinguish handwriting from printed text, they fall short in class variety and document diversity. We demonstrate the limitations of training on existing datasets when solving the National Archives Form Semantic Segmentation dataset (NAFSS), a dataset which we introduce. To address these limitations, we propose the most comprehensive document semantic segmentation synthesis pipeline to date, incorporating preprinted text, handwriting, and document backgrounds from over 10 sources to create the Document Element Layer INtegration Ensemble 8K, or DELINE8K dataset. Our customized dataset exhibits superior performance on the NAFSS benchmark, demonstrating it as a promising tool in further research. The DELINE8K dataset is available at https://github.com/Tahlor/deline8k.
TRACE: A Differentiable Approach to Line-level Stroke Recovery for Offline Handwritten Text
May 24, 2021
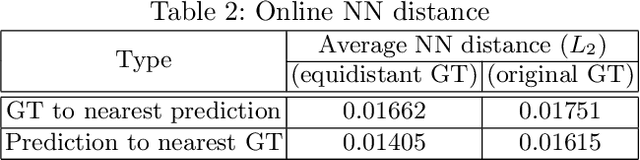
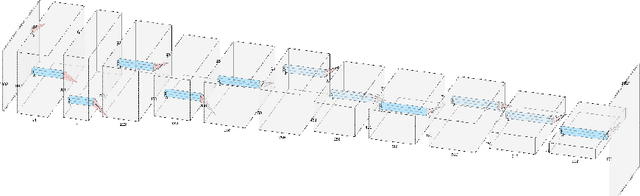
Stroke order and velocity are helpful features in the fields of signature verification, handwriting recognition, and handwriting synthesis. Recovering these features from offline handwritten text is a challenging and well-studied problem. We propose a new model called TRACE (Trajectory Recovery by an Adaptively-trained Convolutional Encoder). TRACE is a differentiable approach that uses a convolutional recurrent neural network (CRNN) to infer temporal stroke information from long lines of offline handwritten text with many characters and dynamic time warping (DTW) to align predictions and ground truth points. TRACE is perhaps the first system to be trained end-to-end on entire lines of text of arbitrary width and does not require the use of dynamic exemplars. Moreover, the system does not require images to undergo any pre-processing, nor do the predictions require any post-processing. Consequently, the recovered trajectory is differentiable and can be used as a loss function for other tasks, including synthesizing offline handwritten text. We demonstrate that temporal stroke information recovered by TRACE from offline data can be used for handwriting synthesis and establish the first benchmarks for a stroke trajectory recovery system trained on the IAM online handwriting dataset.