 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLeveraging Semantic Segmentation Masks with Embeddings for Fine-Grained Form Classification
Paper and Code
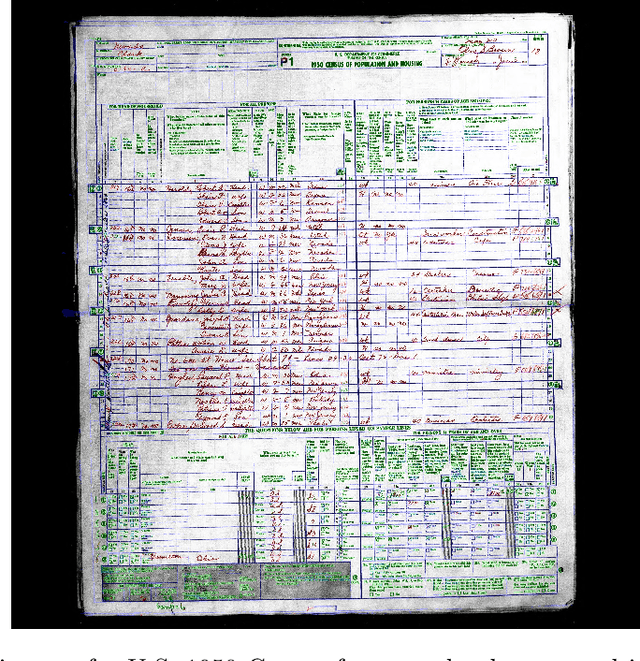
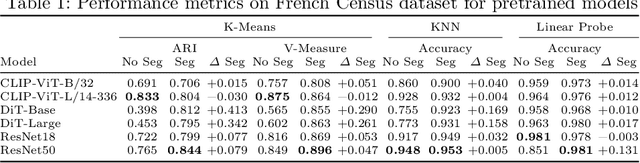

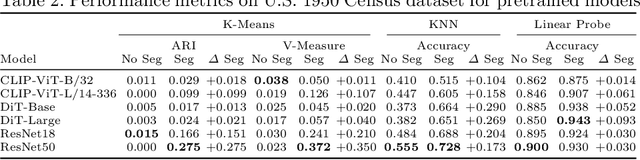
Efficient categorization of historical documents is crucial for fields such as genealogy, legal research, and historical scholarship, where manual classification is impractical for large collections due to its labor-intensive and error-prone nature. To address this, we propose a representational learning strategy that integrates semantic segmentation and deep learning models -- ResNets, CLIP, the Document Image Transformer (DiT), and masked auto-encoders (MAE) -- to generate embeddings that capture document features without predefined labels. To the best of our knowledge, we are the first to evaluate embeddings on fine-grained, unsupervised form classification. To improve these embeddings, we propose to first employ semantic segmentation as a preprocessing step. We contribute two novel datasets -- French 19th-century and U.S. 1950 Census records -- to demonstrate our approach. Our results show the effectiveness of these various embedding techniques in distinguishing similar document types and indicate that applying semantic segmentation can greatly improve clustering and classification results. The census datasets are available at \href{https://github.com/tahlor/census_forms}{https://github.com/tahlor/census\_forms}.