 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Tiny Time-series Transformer: Low-latency High-throughput Classification of Astronomical Transients using Deep Model Compression
Mar 15, 2023A new golden age in astronomy is upon us, dominated by data. Large astronomical surveys are broadcasting unprecedented rates of information, demanding machine learning as a critical component in modern scientific pipelines to handle the deluge of data. The upcoming Legacy Survey of Space and Time (LSST) of the Vera C. Rubin Observatory will raise the big-data bar for time-domain astronomy, with an expected 10 million alerts per-night, and generating many petabytes of data over the lifetime of the survey. Fast and efficient classification algorithms that can operate in real-time, yet robustly and accurately, are needed for time-critical events where additional resources can be sought for follow-up analyses. In order to handle such data, state-of-the-art deep learning architectures coupled with tools that leverage modern hardware accelerators are essential. We showcase how the use of modern deep compression methods can achieve a $18\times$ reduction in model size, whilst preserving classification performance. We also show that in addition to the deep compression techniques, careful choice of file formats can improve inference latency, and thereby throughput of alerts, on the order of $8\times$ for local processing, and $5\times$ in a live production setting. To test this in a live setting, we deploy this optimised version of the original time-series transformer, t2, into the community alert broking system of FINK on real Zwicky Transient Facility (ZTF) alert data, and compare throughput performance with other science modules that exist in FINK. The results shown herein emphasise the time-series transformer's suitability for real-time classification at LSST scale, and beyond, and introduce deep model compression as a fundamental tool for improving deploy-ability and scalable inference of deep learning models for transient classification.
Paying Attention to Astronomical Transients: Photometric Classification with the Time-Series Transformer
May 13, 2021

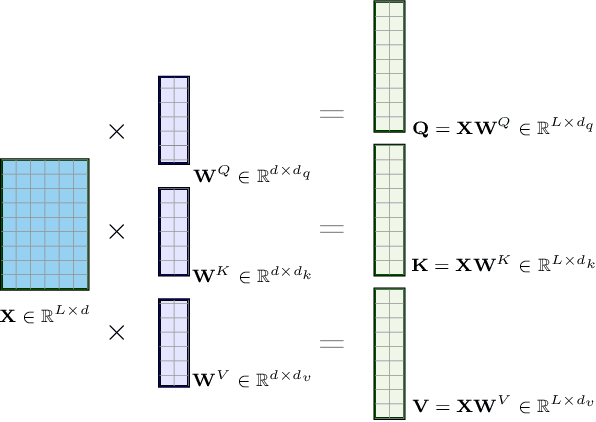
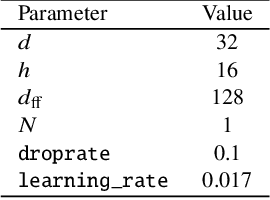
Future surveys such as the Legacy Survey of Space and Time (LSST) of the Vera C. Rubin Observatory will observe an order of magnitude more astrophysical transient events than any previous survey before. With this deluge of photometric data, it will be impossible for all such events to be classified by humans alone. Recent efforts have sought to leverage machine learning methods to tackle the challenge of astronomical transient classification, with ever improving success. Transformers are a recently developed deep learning architecture, first proposed for natural language processing, that have shown a great deal of recent success. In this work we develop a new transformer architecture, which uses multi-head self attention at its core, for general multi-variate time-series data. Furthermore, the proposed time-series transformer architecture supports the inclusion of an arbitrary number of additional features, while also offering interpretability. We apply the time-series transformer to the task of photometric classification, minimising the reliance of expert domain knowledge for feature selection, while achieving results comparable to state-of-the-art photometric classification methods. We achieve a weighted logarithmic-loss of 0.507 on imbalanced data in a representative setting using data from the Photometric LSST Astronomical Time-Series Classification Challenge (PLAsTiCC). Moreover, we achieve a micro-averaged receiver operating characteristic area under curve of 0.98 and micro-averaged precision-recall area under curve of 0.87.