 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExplainable AI Using Inherently Interpretable Components for Wearable-based Health Monitoring
Mar 13, 2026The use of wearables in medicine and wellness, enabled by AI-based models, offers tremendous potential for real-time monitoring and interpretable event detection. Explainable AI (XAI) is required to assess what models have learned and build trust in model outputs, for patients, healthcare professionals, model developers, and domain experts alike. Explaining AI decisions made on time-series data recorded by wearables is especially challenging due to the data's complex nature and temporal dependencies. Too often, explainability using interpretable features leads to performance loss. We propose a novel XAI method that combines explanation spaces and concept-based explanations to explain AI predictions on time-series data. By using Inherently Interpretable Components (IICs), which encapsulate domain-specific, interpretable concepts within a custom explanation space, we preserve the performance of models trained on time series while achieving the interpretability of concept-based explanations based on extracted features. Furthermore, we define a domain-specific set of IICs for wearable-based health monitoring and demonstrate their usability in real applications, including state assessment and epileptic seizure detection.
Identifying the Complete Correlation Structure in Large-Scale High-Dimensional Data Sets with Local False Discovery Rates
Jun 01, 2023
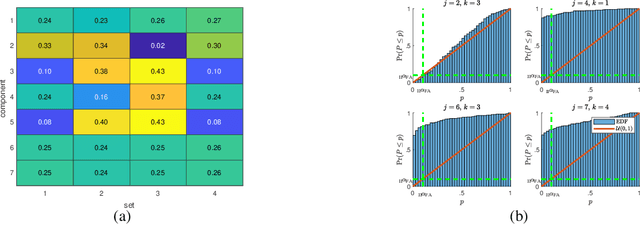
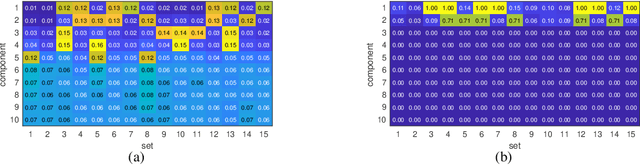
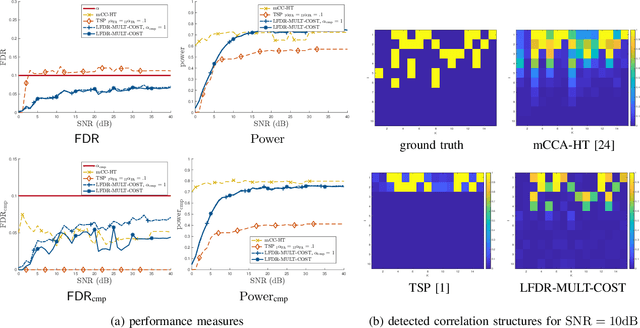
The identification of the dependent components in multiple data sets is a fundamental problem in many practical applications. The challenge in these applications is that often the data sets are high-dimensional with few observations or available samples and contain latent components with unknown probability distributions. A novel mathematical formulation of this problem is proposed, which enables the inference of the underlying correlation structure with strict false positive control. In particular, the false discovery rate is controlled at a pre-defined threshold on two levels simultaneously. The deployed test statistics originate in the sample coherence matrix. The required probability models are learned from the data using the bootstrap. Local false discovery rates are used to solve the multiple hypothesis testing problem. Compared to the existing techniques in the literature, the developed technique does not assume an a priori correlation structure and work well when the number of data sets is large while the number of observations is small. In addition, it can handle the presence of distributional uncertainties, heavy-tailed noise, and outliers.