 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHybrid Rendering for Multimodal Autonomous Driving: Merging Neural and Physics-Based Simulation
Mar 12, 2025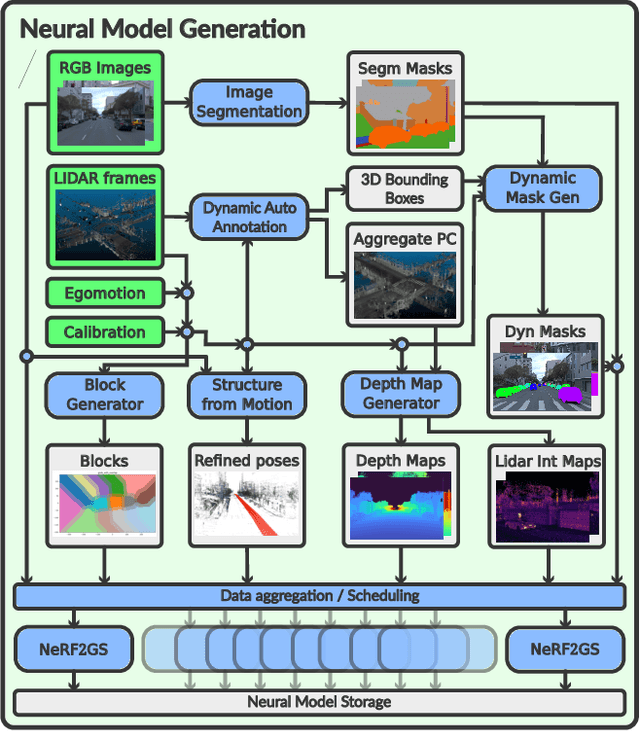
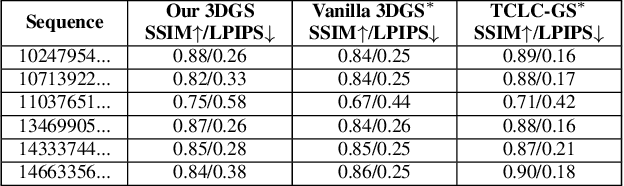

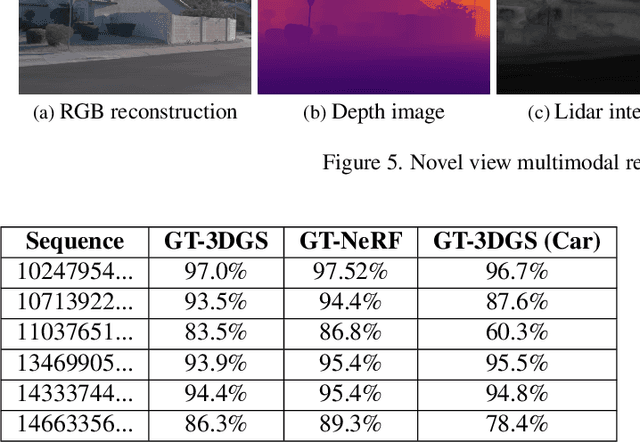
Neural reconstruction models for autonomous driving simulation have made significant strides in recent years, with dynamic models becoming increasingly prevalent. However, these models are typically limited to handling in-domain objects closely following their original trajectories. We introduce a hybrid approach that combines the strengths of neural reconstruction with physics-based rendering. This method enables the virtual placement of traditional mesh-based dynamic agents at arbitrary locations, adjustments to environmental conditions, and rendering from novel camera viewpoints. Our approach significantly enhances novel view synthesis quality -- especially for road surfaces and lane markings -- while maintaining interactive frame rates through our novel training method, NeRF2GS. This technique leverages the superior generalization capabilities of NeRF-based methods and the real-time rendering speed of 3D Gaussian Splatting (3DGS). We achieve this by training a customized NeRF model on the original images with depth regularization derived from a noisy LiDAR point cloud, then using it as a teacher model for 3DGS training. This process ensures accurate depth, surface normals, and camera appearance modeling as supervision. With our block-based training parallelization, the method can handle large-scale reconstructions (greater than or equal to 100,000 square meters) and predict segmentation masks, surface normals, and depth maps. During simulation, it supports a rasterization-based rendering backend with depth-based composition and multiple camera models for real-time camera simulation, as well as a ray-traced backend for precise LiDAR simulation.
Multimodal Foundational Models for Unsupervised 3D General Obstacle Detection
Aug 22, 2024



Current autonomous driving perception models primarily rely on supervised learning with predefined categories. However, these models struggle to detect general obstacles not included in the fixed category set due to their variability and numerous edge cases. To address this issue, we propose a combination of multimodal foundational model-based obstacle segmentation with traditional unsupervised computational geometry-based outlier detection. Our approach operates offline, allowing us to leverage non-causality, and utilizes training-free methods. This enables the detection of general obstacles in 3D without the need for expensive retraining. To overcome the limitations of publicly available obstacle detection datasets, we collected and annotated our dataset, which includes various obstacles even in distant regions.
Compute-Efficient Active Learning
Jan 15, 2024



Active learning, a powerful paradigm in machine learning, aims at reducing labeling costs by selecting the most informative samples from an unlabeled dataset. However, the traditional active learning process often demands extensive computational resources, hindering scalability and efficiency. In this paper, we address this critical issue by presenting a novel method designed to alleviate the computational burden associated with active learning on massive datasets. To achieve this goal, we introduce a simple, yet effective method-agnostic framework that outlines how to strategically choose and annotate data points, optimizing the process for efficiency while maintaining model performance. Through case studies, we demonstrate the effectiveness of our proposed method in reducing computational costs while maintaining or, in some cases, even surpassing baseline model outcomes. Code is available at https://github.com/aimotive/Compute-Efficient-Active-Learning.
aiMotive Dataset: A Multimodal Dataset for Robust Autonomous Driving with Long-Range Perception
Nov 17, 2022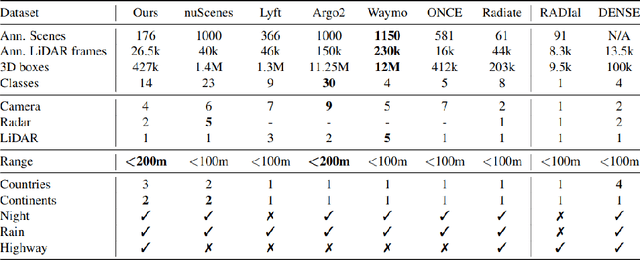
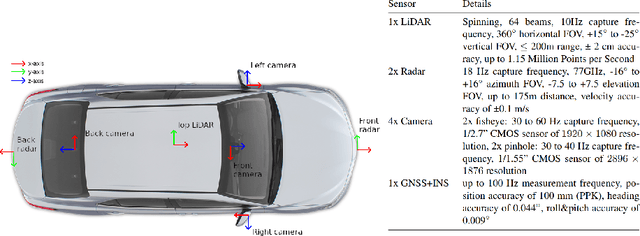
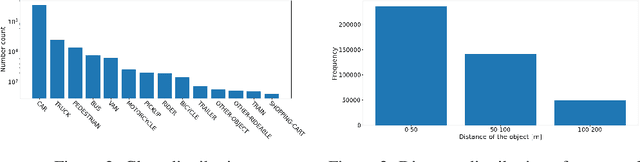

Autonomous driving is a popular research area within the computer vision research community. Since autonomous vehicles are highly safety-critical, ensuring robustness is essential for real-world deployment. While several public multimodal datasets are accessible, they mainly comprise two sensor modalities (camera, LiDAR) which are not well suited for adverse weather. In addition, they lack far-range annotations, making it harder to train neural networks that are the base of a highway assistant function of an autonomous vehicle. Therefore, we introduce a multimodal dataset for robust autonomous driving with long-range perception. The dataset consists of 176 scenes with synchronized and calibrated LiDAR, camera, and radar sensors covering a 360-degree field of view. The collected data was captured in highway, urban, and suburban areas during daytime, night, and rain and is annotated with 3D bounding boxes with consistent identifiers across frames. Furthermore, we trained unimodal and multimodal baseline models for 3D object detection. Data are available at \url{https://github.com/aimotive/aimotive_dataset}.