 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning to diagnose common thorax diseases on chest radiographs from radiology reports in Vietnamese
Sep 11, 2022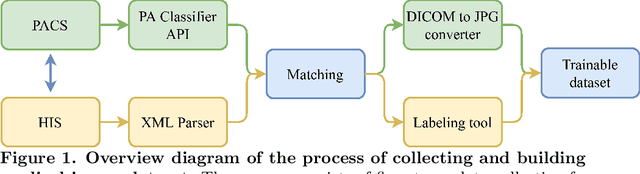
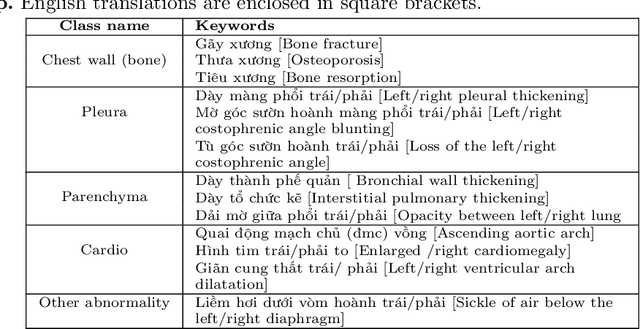

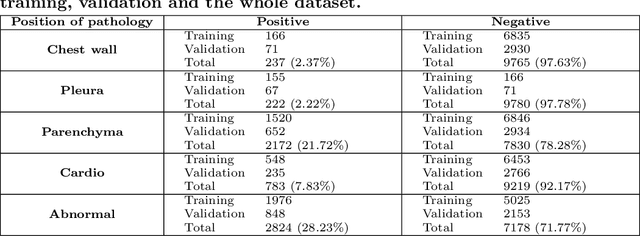
We propose a data collecting and annotation pipeline that extracts information from Vietnamese radiology reports to provide accurate labels for chest X-ray (CXR) images. This can benefit Vietnamese radiologists and clinicians by annotating data that closely match their endemic diagnosis categories which may vary from country to country. To assess the efficacy of the proposed labeling technique, we built a CXR dataset containing 9,752 studies and evaluated our pipeline using a subset of this dataset. With an F1-score of at least 0.9923, the evaluation demonstrates that our labeling tool performs precisely and consistently across all classes. After building the dataset, we train deep learning models that leverage knowledge transferred from large public CXR datasets. We employ a variety of loss functions to overcome the curse of imbalanced multi-label datasets and conduct experiments with various model architectures to select the one that delivers the best performance. Our best model (CheXpert-pretrained EfficientNet-B2) yields an F1-score of 0.6989 (95% CI 0.6740, 0.7240), AUC of 0.7912, sensitivity of 0.7064 and specificity of 0.8760 for the abnormal diagnosis in general. Finally, we demonstrate that our coarse classification (based on five specific locations of abnormalities) yields comparable results to fine classification (twelve pathologies) on the benchmark CheXpert dataset for general anomaly detection while delivering better performance in terms of the average performance of all classes.