 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSynergetic Reconstruction from 2D Pose and 3D Motion for Wide-Space Multi-Person Video Motion Capture in the Wild
Jan 16, 2020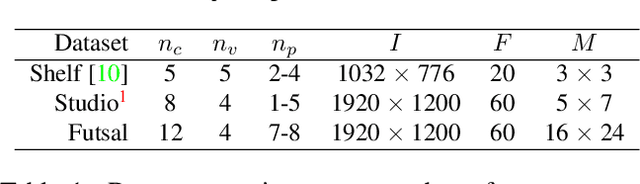
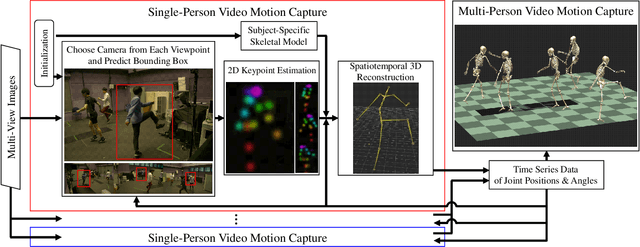
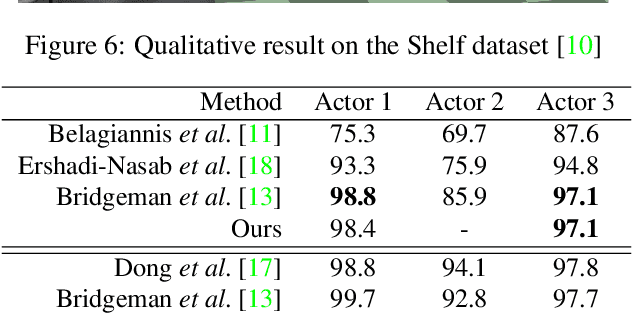
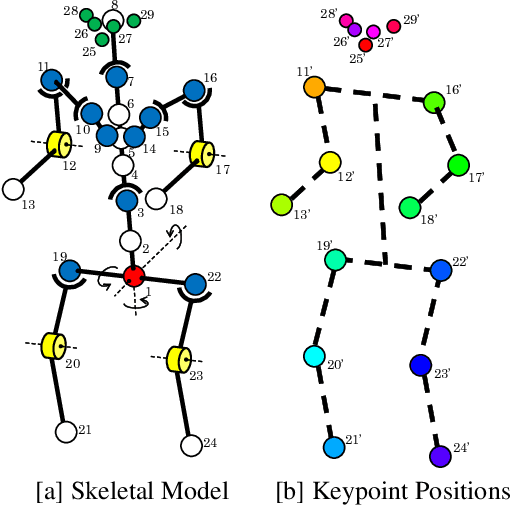
Although many studies have been made on markerless motion capture, it has not been applied to real sports or concerts. In this paper, we propose a markerless motion capture method with spatiotemporal accuracy and smoothness from multiple cameras, even in wide and multi-person environments. The key idea is predicting each person's 3D pose and determining the bounding box of multi-camera images small enough. This prediction and spatiotemporal filtering based on human skeletal structure eases 3D reconstruction of the person and yields accuracy. The accurate 3D reconstruction is then used to predict the bounding box of each camera image in the next frame. This is a feedback from 3D motion to 2D pose, and provides a synergetic effect to the total performance of video motion capture. We demonstrate the method using various datasets and a real sports field. The experimental results show the mean per joint position error was 31.6mm and the percentage of correct parts was 99.3% under five people moving dynamically, with satisfying the range of motion. Video demonstration, datasets, and additional materials are posted on our project page.
Video Motion Capture from the Part Confidence Maps of Multi-Camera Images by Spatiotemporal Filtering Using the Human Skeletal Model
Dec 10, 2019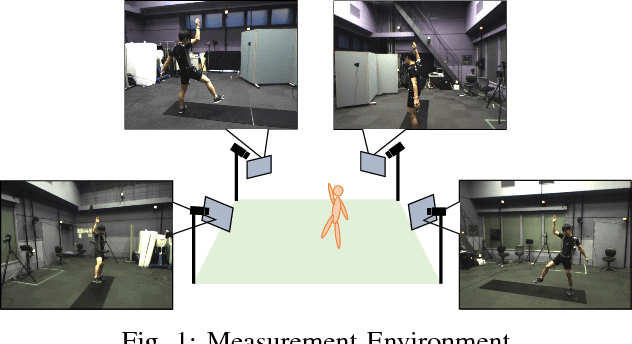

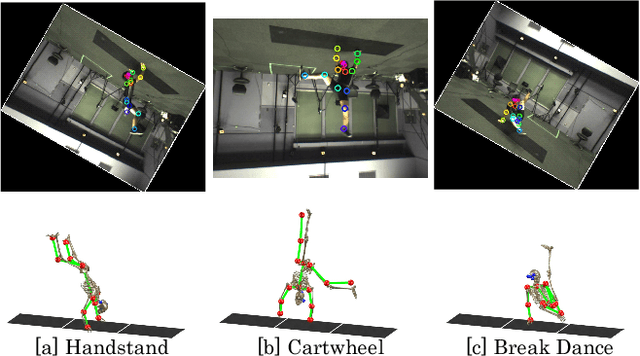
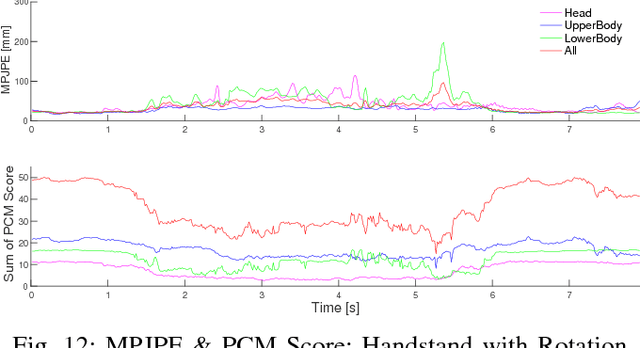
This paper discusses video motion capture, namely, 3D reconstruction of human motion from multi-camera images. After the Part Confidence Maps are computed from each camera image, the proposed spatiotemporal filter is applied to deliver the human motion data with accuracy and smoothness for human motion analysis. The spatiotemporal filter uses the human skeleton and mixes temporal smoothing in two-time inverse kinematics computations. The experimental results show that the mean per joint position error was 26.1mm for regular motions and 38.8mm for inverted motions.
Sensorimotor learning for artificial body perception
Jan 15, 2019
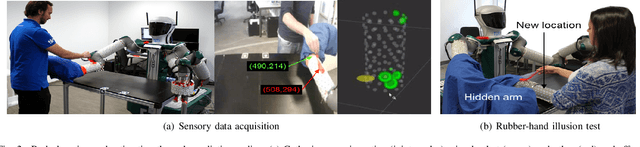
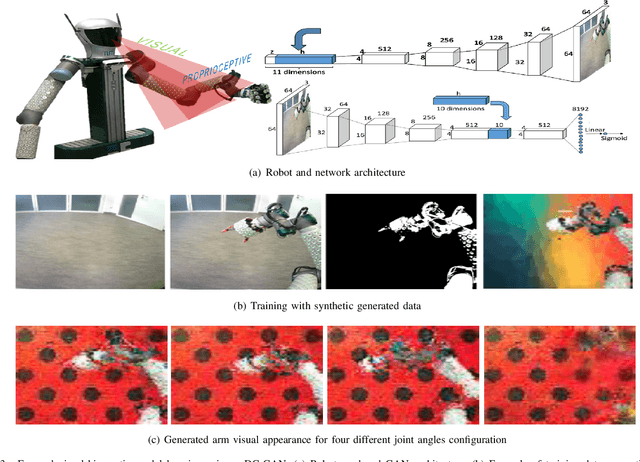

Artificial self-perception is the machine ability to perceive its own body, i.e., the mastery of modal and intermodal contingencies of performing an action with a specific sensors/actuators body configuration. In other words, the spatio-temporal patterns that relate its sensors (e.g. visual, proprioceptive, tactile, etc.), its actions and its body latent variables are responsible of the distinction between its own body and the rest of the world. This paper describes some of the latest approaches for modelling artificial body self-perception: from Bayesian estimation to deep learning. Results show the potential of these free-model unsupervised or semi-supervised crossmodal/intermodal learning approaches. However, there are still challenges that should be overcome before we achieve artificial multisensory body perception.