 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMaGRITTe: Manipulative and Generative 3D Realization from Image, Topview and Text
Mar 30, 2024



The generation of 3D scenes from user-specified conditions offers a promising avenue for alleviating the production burden in 3D applications. Previous studies required significant effort to realize the desired scene, owing to limited control conditions. We propose a method for controlling and generating 3D scenes under multimodal conditions using partial images, layout information represented in the top view, and text prompts. Combining these conditions to generate a 3D scene involves the following significant difficulties: (1) the creation of large datasets, (2) reflection on the interaction of multimodal conditions, and (3) domain dependence of the layout conditions. We decompose the process of 3D scene generation into 2D image generation from the given conditions and 3D scene generation from 2D images. 2D image generation is achieved by fine-tuning a pretrained text-to-image model with a small artificial dataset of partial images and layouts, and 3D scene generation is achieved by layout-conditioned depth estimation and neural radiance fields (NeRF), thereby avoiding the creation of large datasets. The use of a common representation of spatial information using 360-degree images allows for the consideration of multimodal condition interactions and reduces the domain dependence of the layout control. The experimental results qualitatively and quantitatively demonstrated that the proposed method can generate 3D scenes in diverse domains, from indoor to outdoor, according to multimodal conditions.
Enhancement of Novel View Synthesis Using Omnidirectional Image Completion
Mar 18, 2022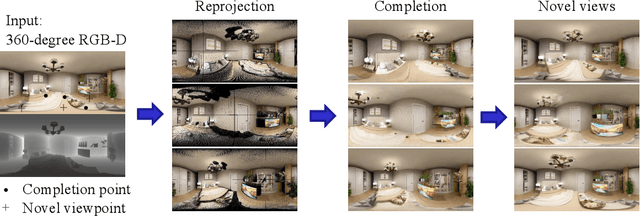
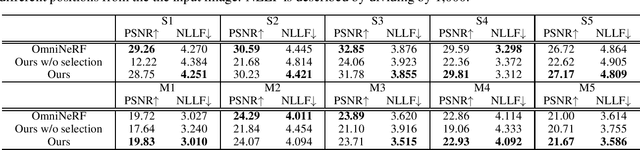
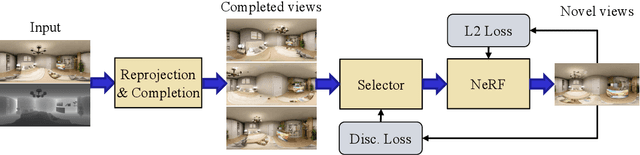
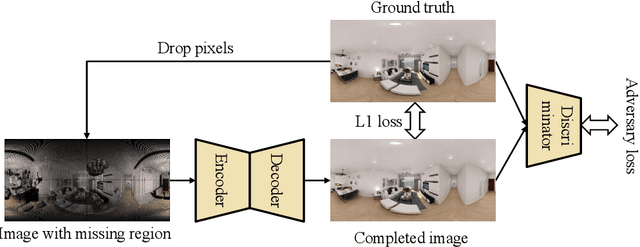
We present a method for synthesizing novel views from a single 360-degree image based on the neural radiance field (NeRF) . Prior studies rely on the neighborhood interpolation capability of multi-layer perceptrons to complete missing regions caused by occlusion and zooming, and this leads to artifacts. In the proposed method, the input image is reprojected to 360-degree images at other camera positions, the missing regions of the reprojected images are completed by a self-supervised trained generative model, and the completed images are utilized to train the NeRF. Because multiple completed images contain inconsistencies in 3D, we introduce a method to train NeRF while dynamically selecting a sparse set of completed images, to reduce the discrimination error of the synthesized views with real images. Experiments indicate that the proposed method can synthesize plausible novel views while preserving the features of the scene for both artificial and real-world data.
Spherical Image Generation from a Single Normal Field of View Image by Considering Scene Symmetry
Jan 09, 2020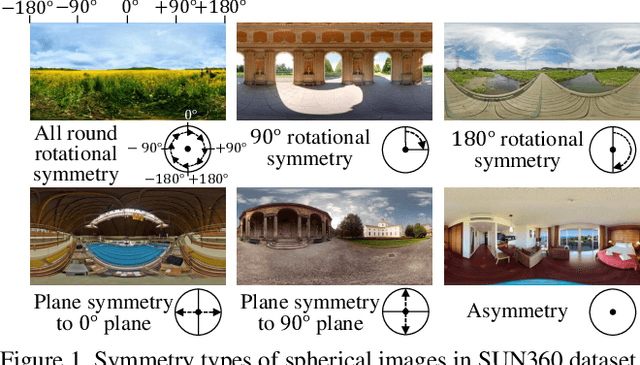

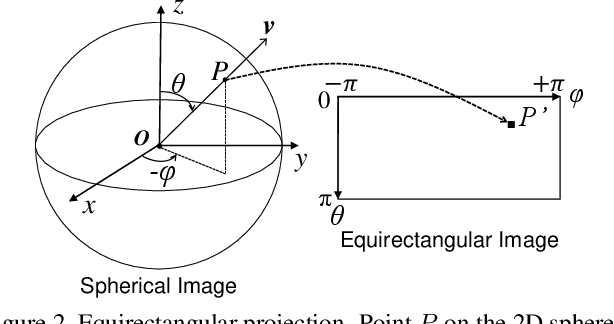

Spherical images taken in all directions (360 degrees) allow representing the surroundings of the subject and the space itself, providing an immersive experience to the viewers. Generating a spherical image from a single normal-field-of-view (NFOV) image is convenient and considerably expands the usage scenarios because there is no need to use a specific panoramic camera or take images from multiple directions; however, it is still a challenging and unsolved problem. The primary challenge is controlling the high degree of freedom involved in generating a wide area that includes the all directions of the desired plausible spherical image. On the other hand, scene symmetry is a basic property of the global structure of the spherical images, such as rotation symmetry, plane symmetry and asymmetry. We propose a method to generate spherical image from a single NFOV image, and control the degree of freedom of the generated regions using scene symmetry. We incorporate scene-symmetry parameters as latent variables into conditional variational autoencoders, following which we learn the conditional probability of spherical images for NFOV images and scene symmetry. Furthermore, the probability density functions are represented using neural networks, and scene symmetry is implemented using both circular shift and flip of the hidden variables. Our experiments show that the proposed method can generate various plausible spherical images, controlled from symmetric to asymmetric.