 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLadder Siamese Network: a Method and Insights for Multi-level Self-Supervised Learning
Nov 25, 2022



Siamese-network-based self-supervised learning (SSL) suffers from slow convergence and instability in training. To alleviate this, we propose a framework to exploit intermediate self-supervisions in each stage of deep nets, called the Ladder Siamese Network. Our self-supervised losses encourage the intermediate layers to be consistent with different data augmentations to single samples, which facilitates training progress and enhances the discriminative ability of the intermediate layers themselves. While some existing work has already utilized multi-level self supervisions in SSL, ours is different in that 1) we reveal its usefulness with non-contrastive Siamese frameworks in both theoretical and empirical viewpoints, and 2) ours improves image-level classification, instance-level detection, and pixel-level segmentation simultaneously. Experiments show that the proposed framework can improve BYOL baselines by 1.0% points in ImageNet linear classification, 1.2% points in COCO detection, and 3.1% points in PASCAL VOC segmentation. In comparison with the state-of-the-art methods, our Ladder-based model achieves competitive and balanced performances in all tested benchmarks without causing large degradation in one.
Deep Learning Based Multi-modal Addressee Recognition in Visual Scenes with Utterances
Sep 12, 2018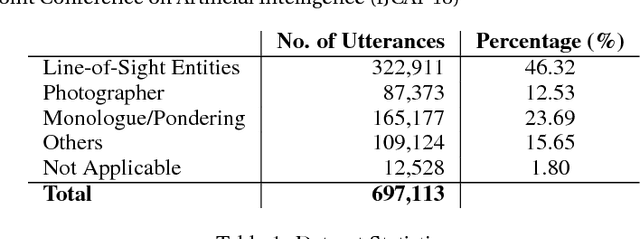

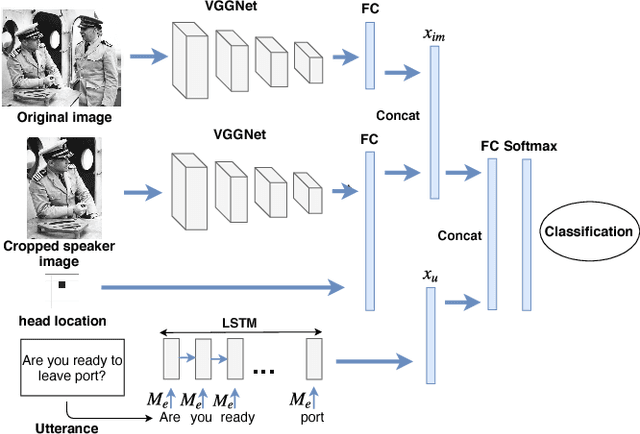
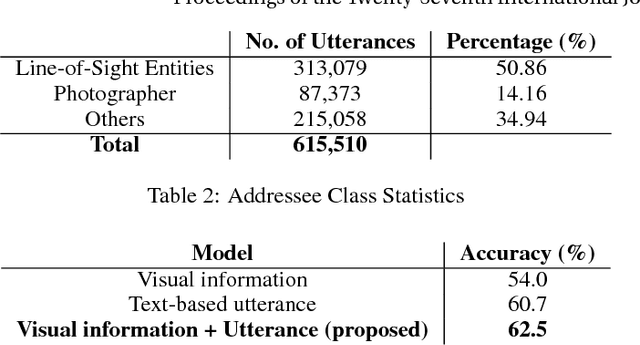
With the widespread use of intelligent systems, such as smart speakers, addressee recognition has become a concern in human-computer interaction, as more and more people expect such systems to understand complicated social scenes, including those outdoors, in cafeterias, and hospitals. Because previous studies typically focused only on pre-specified tasks with limited conversational situations such as controlling smart homes, we created a mock dataset called Addressee Recognition in Visual Scenes with Utterances (ARVSU) that contains a vast body of image variations in visual scenes with an annotated utterance and a corresponding addressee for each scenario. We also propose a multi-modal deep-learning-based model that takes different human cues, specifically eye gazes and transcripts of an utterance corpus, into account to predict the conversational addressee from a specific speaker's view in various real-life conversational scenarios. To the best of our knowledge, we are the first to introduce an end-to-end deep learning model that combines vision and transcripts of utterance for addressee recognition. As a result, our study suggests that future addressee recognition can reach the ability to understand human intention in many social situations previously unexplored, and our modality dataset is a first step in promoting research in this field.