 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSoft-Deep Boltzmann Machines
Jun 21, 2015



We present a layered Boltzmann machine (BM) that can better exploit the advantages of a distributed representation. It is widely believed that deep BMs (DBMs) have far greater representational power than its shallow counterpart, restricted Boltzmann machines (RBMs). However, this expectation on the supremacy of DBMs over RBMs has not ever been validated in a theoretical fashion. In this paper, we provide both theoretical and empirical evidences that the representational power of DBMs can be actually rather limited in taking advantages of distributed representations. We propose an approximate measure for the representational power of a BM regarding to the efficiency of a distributed representation. With this measure, we show a surprising fact that DBMs can make inefficient use of distributed representations. Based on these observations, we propose an alternative BM architecture, which we dub soft-deep BMs (sDBMs). We show that sDBMs can more efficiently exploit the distributed representations in terms of the measure. Experiments demonstrate that sDBMs outperform several state-of-the-art models, including DBMs, in generative tasks on binarized MNIST and Caltech-101 silhouettes.
Variational Optimization of Annealing Schedules
Mar 27, 2015
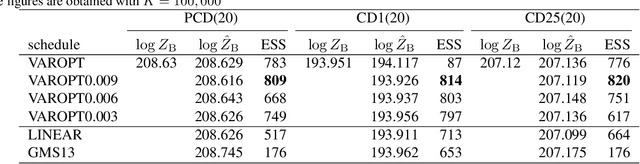


Annealed importance sampling (AIS) is a common algorithm to estimate partition functions of useful stochastic models. One important problem for obtaining accurate AIS estimates is the selection of an annealing schedule. Conventionally, an annealing schedule is often determined heuristically or is simply set as a linearly increasing sequence. In this paper, we propose an algorithm for the optimal schedule by deriving a functional that dominates the AIS estimation error and by numerically minimizing this functional. We experimentally demonstrate that the proposed algorithm mostly outperforms conventional scheduling schemes with large quantization numbers.
Approximated Infomax Early Stopping: Revisiting Gaussian RBMs on Natural Images
Jan 06, 2014


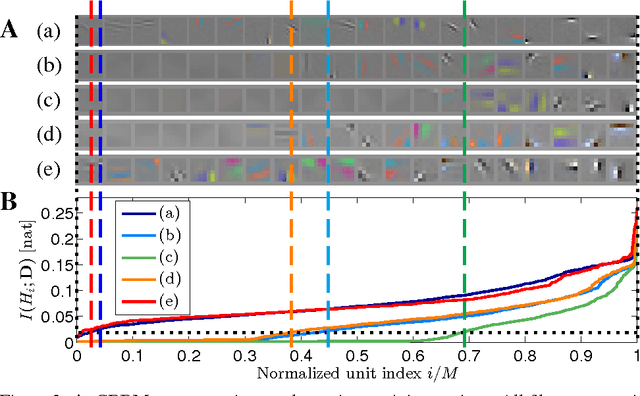
We pursue an early stopping technique that helps Gaussian Restricted Boltzmann Machines (GRBMs) to gain good natural image representations in terms of overcompleteness and data fitting. GRBMs are widely considered as an unsuitable model for natural images because they gain non-overcomplete representations which include uniform filters that do not represent useful image features. We have recently found that GRBMs once gain and subsequently lose useful filters during their training, contrary to this common perspective. We attribute this phenomenon to a tradeoff between overcompleteness of GRBM representations and data fitting. To gain GRBM representations that are overcomplete and fit data well, we propose a measure for GRBM representation quality, approximated mutual information, and an early stopping technique based on this measure. The proposed method boosts performance of classifiers trained on GRBM representations.