 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA CMOL-Like Memristor-CMOS Neuromorphic Chip-Core Demonstrating Stochastic Binary STDP
Sep 13, 2022



The advent of nanoscale memristors raised hopes of being able to build CMOL (CMOS/nanowire/moLecular) type ultra-dense in-memory-computing circuit architectures. In CMOL, nanoscale memristors would be fabricated at the intersection of nanowires. The CMOL concept can be exploited in neuromorphic hardware by fabricating lower-density neurons on CMOS and placing massive analog synaptic connectivity with nanowire and nanoscale-memristor fabric post-fabricated on top. However, technical problems have hindered such developments for presently available reliable commercial monolithic CMOS-memristor technologies. On one hand, each memristor needs a MOS selector transistor in series to guarantee forming and programming operations in large arrays. This results in compound MOS-memristor synapses (called 1T1R) which are no longer synapses at the crossing of nanowires. On the other hand, memristors do not yet constitute highly reliable, stable analog memories for massive analog-weight synapses with gradual learning. Here we demonstrate a pseudo-CMOL monolithic chip core that circumvents the two technical problems mentioned above by (a) exploiting a CMOL-like geometrical chip layout technique to improve density despite the 1T1R limitation, and (b) exploiting a binary weight stochastic Spike-Timing-Dependent-Plasticity (STDP) learning rule that takes advantage of the more reliable binary memory capability of the memristors used. Experimental results are provided for a spiking neural network (SNN) CMOL-core with 64 input neurons, 64 output neurons, and 4096 1T1R synapses, fabricated in 130nm CMOS with 200nm-sized Ti/HfOx/TiN memristors on top. The CMOL-core uses query-driven event read-out, which allows for memristor variability insensitive computations.
Fully-parallel Convolutional Neural Network Hardware
Jun 22, 2020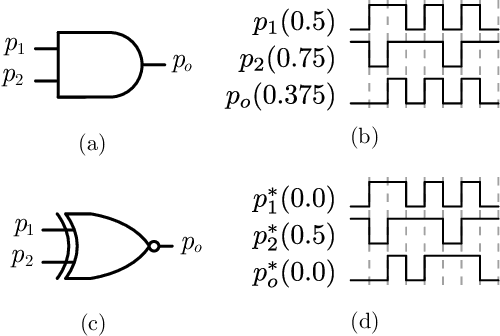
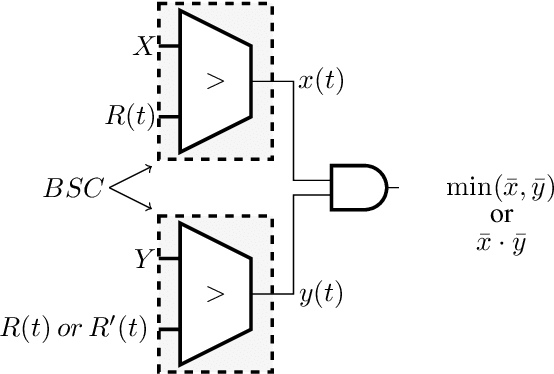
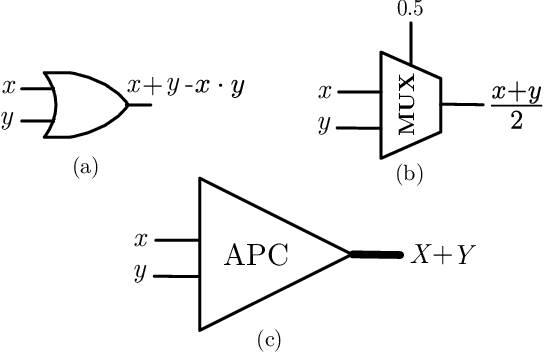
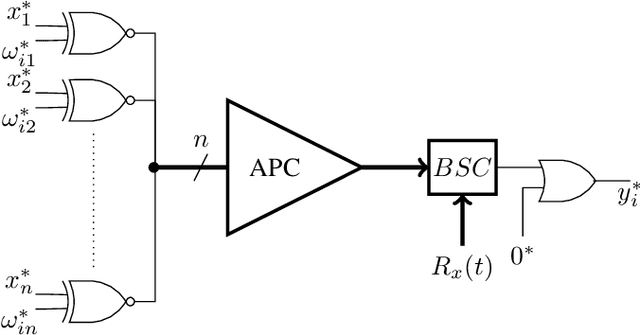
A new trans-disciplinary knowledge area, Edge Artificial Intelligence or Edge Intelligence, is beginning to receive a tremendous amount of interest from the machine learning community due to the ever increasing popularization of the Internet of Things (IoT). Unfortunately, the incorporation of AI characteristics to edge computing devices presents the drawbacks of being power and area hungry for typical machine learning techniques such as Convolutional Neural Networks (CNN). In this work, we propose a new power-and-area-efficient architecture for implementing Articial Neural Networks (ANNs) in hardware, based on the exploitation of correlation phenomenon in Stochastic Computing (SC) systems. The architecture purposed can solve the difficult implementation challenges that SC presents for CNN applications, such as the high resources used in binary-tostochastic conversion, the inaccuracy produced by undesired correlation between signals, and the stochastic maximum function implementation. Compared with traditional binary logic implementations, experimental results showed an improvement of 19.6x and 6.3x in terms of speed performance and energy efficiency, for the FPGA implementation. We have also realized a full VLSI implementation of the proposed SC-CNN architecture demonstrating that our optimization achieve a 18x area reduction over previous SC-DNN architecture VLSI implementation in a comparable technological node. For the first time, a fully-parallel CNN as LENET-5 is embedded and tested in a single FPGA, showing the benefits of using stochastic computing for embedded applications, in contrast to traditional binary logic implementations.