 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFully-parallel Convolutional Neural Network Hardware
Jun 22, 2020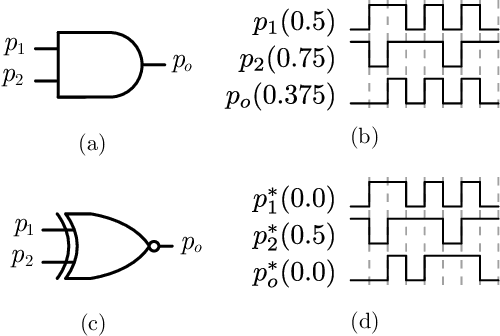
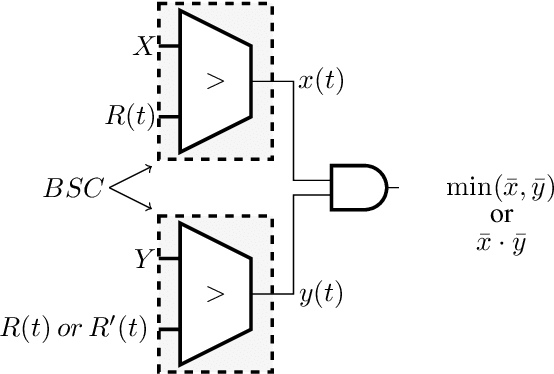
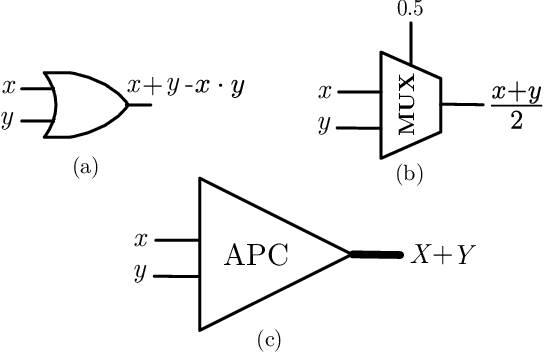
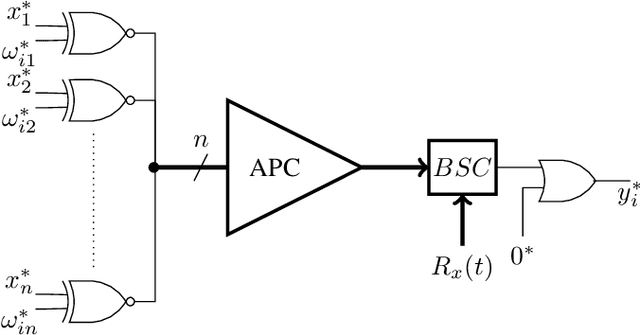
A new trans-disciplinary knowledge area, Edge Artificial Intelligence or Edge Intelligence, is beginning to receive a tremendous amount of interest from the machine learning community due to the ever increasing popularization of the Internet of Things (IoT). Unfortunately, the incorporation of AI characteristics to edge computing devices presents the drawbacks of being power and area hungry for typical machine learning techniques such as Convolutional Neural Networks (CNN). In this work, we propose a new power-and-area-efficient architecture for implementing Articial Neural Networks (ANNs) in hardware, based on the exploitation of correlation phenomenon in Stochastic Computing (SC) systems. The architecture purposed can solve the difficult implementation challenges that SC presents for CNN applications, such as the high resources used in binary-tostochastic conversion, the inaccuracy produced by undesired correlation between signals, and the stochastic maximum function implementation. Compared with traditional binary logic implementations, experimental results showed an improvement of 19.6x and 6.3x in terms of speed performance and energy efficiency, for the FPGA implementation. We have also realized a full VLSI implementation of the proposed SC-CNN architecture demonstrating that our optimization achieve a 18x area reduction over previous SC-DNN architecture VLSI implementation in a comparable technological node. For the first time, a fully-parallel CNN as LENET-5 is embedded and tested in a single FPGA, showing the benefits of using stochastic computing for embedded applications, in contrast to traditional binary logic implementations.
Stochastic-based Neural Network hardware acceleration for an efficient ligand-based virtual screening
Jun 03, 2020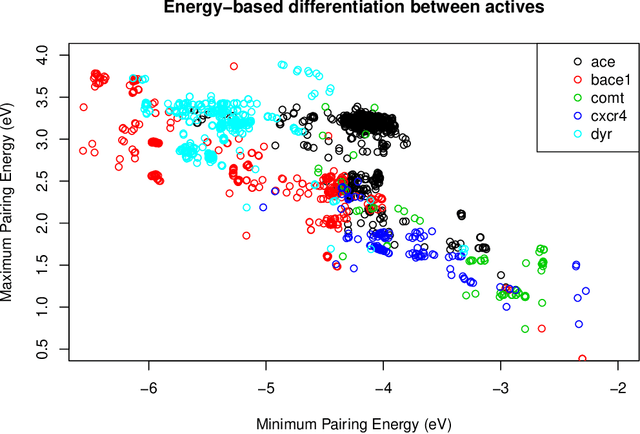
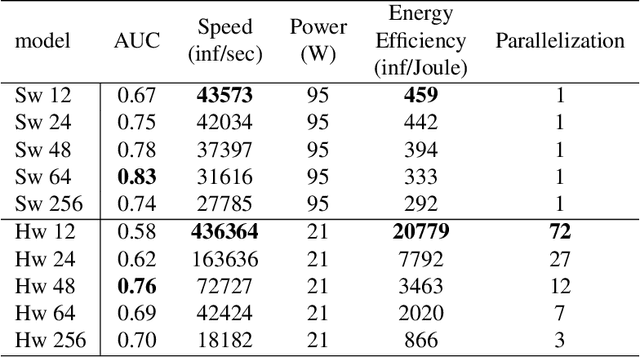
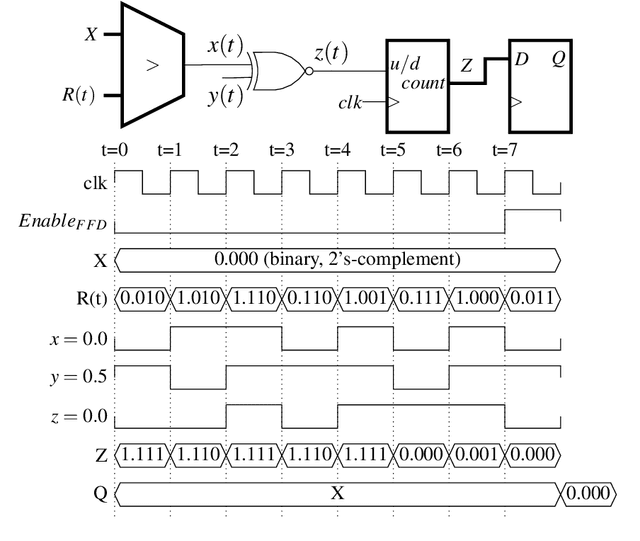
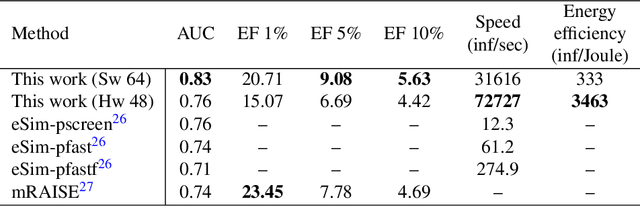
Artificial Neural Networks (ANN) have been popularized in many science and technological areas due to their capacity to solve many complex pattern matching problems. That is the case of Virtual Screening, a research area that studies how to identify those molecular compounds with the highest probability to present biological activity for a therapeutic target. Due to the vast number of small organic compounds and the thousands of targets for which such large-scale screening can potentially be carried out, there has been an increasing interest in the research community to increase both, processing speed and energy efficiency in the screening of molecular databases. In this work, we present a classification model describing each molecule with a single energy-based vector and propose a machine-learning system based on the use of ANNs. Different ANNs are studied with respect to their suitability to identify biochemical similarities. Also, a high-performance and energy-efficient hardware acceleration platform based on the use of stochastic computing is proposed for the ANN implementation. This platform is of utility when screening vast libraries of compounds. As a result, the proposed model showed appreciable improvements with respect previously published works in terms of the main relevant characteristics (accuracy, speed and energy-efficiency).