 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePerformance Evaluation of Deep Learning and Transformer Models Using Multimodal Data for Breast Cancer Classification
Oct 14, 2024Rising breast cancer (BC) occurrence and mortality are major global concerns for women. Deep learning (DL) has demonstrated superior diagnostic performance in BC classification compared to human expert readers. However, the predominant use of unimodal (digital mammography) features may limit the current performance of diagnostic models. To address this, we collected a novel multimodal dataset comprising both imaging and textual data. This study proposes a multimodal DL architecture for BC classification, utilising images (mammograms; four views) and textual data (radiological reports) from our new in-house dataset. Various augmentation techniques were applied to enhance the training data size for both imaging and textual data. We explored the performance of eleven SOTA DL architectures (VGG16, VGG19, ResNet34, ResNet50, MobileNet-v3, EffNet-b0, EffNet-b1, EffNet-b2, EffNet-b3, EffNet-b7, and Vision Transformer (ViT)) as imaging feature extractors. For textual feature extraction, we utilised either artificial neural networks (ANNs) or long short-term memory (LSTM) networks. The combined imaging and textual features were then inputted into an ANN classifier for BC classification, using the late fusion technique. We evaluated different feature extractor and classifier arrangements. The VGG19 and ANN combinations achieved the highest accuracy of 0.951. For precision, the VGG19 and ANN combination again surpassed other CNN and LSTM, ANN based architectures by achieving a score of 0.95. The best sensitivity score of 0.903 was achieved by the VGG16+LSTM. The highest F1 score of 0.931 was achieved by VGG19+LSTM. Only the VGG16+LSTM achieved the best area under the curve (AUC) of 0.937, with VGG16+LSTM closely following with a 0.929 AUC score.
Oversampling Log Messages Using a Sequence Generative Adversarial Network for Anomaly Detection and Classification
Jan 04, 2020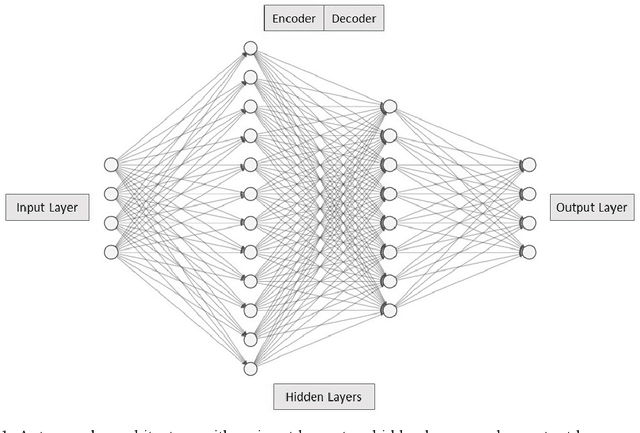
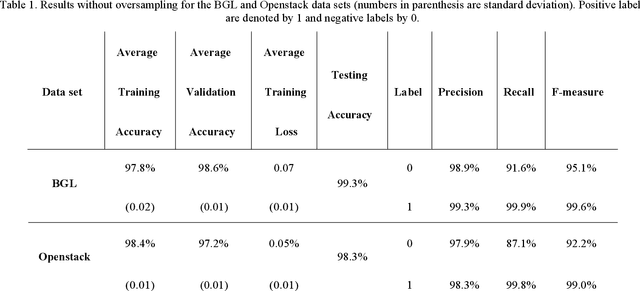
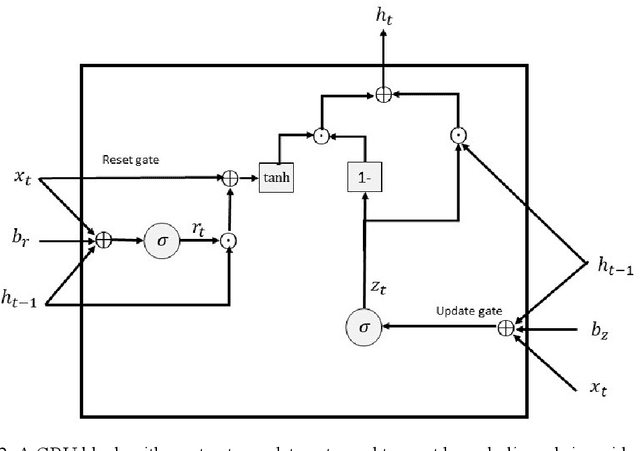
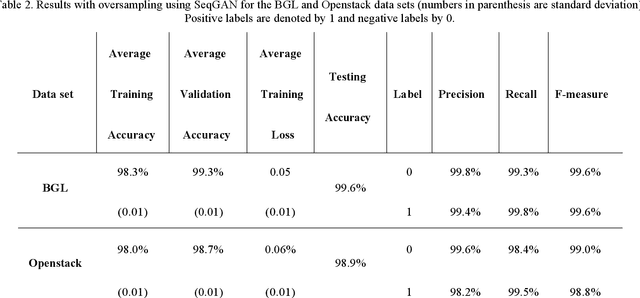
Dealing with imbalanced data is one of the main challenges in machine/deep learning algorithms for classification. This issue is more important with log message data as it is typically very imbalanced and negative logs are rare. In this paper, a model is proposed to generate text log messages using a SeqGAN network. Then features are extracted using an Autoencoder and anomaly detection is done using a GRU network. The proposed model is evaluated with two imbalanced log data sets, namely BGL and Openstack. Results are presented which show that oversampling and balancing data increases the accuracy of anomaly detection and classification.
Log Message Anomaly Detection and Classification Using Auto-B/LSTM and Auto-GRU
Nov 20, 2019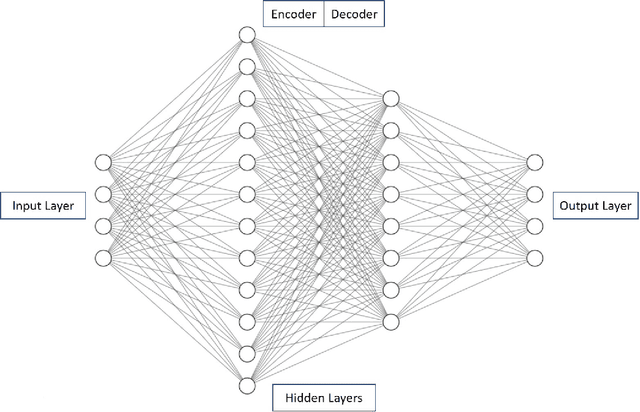
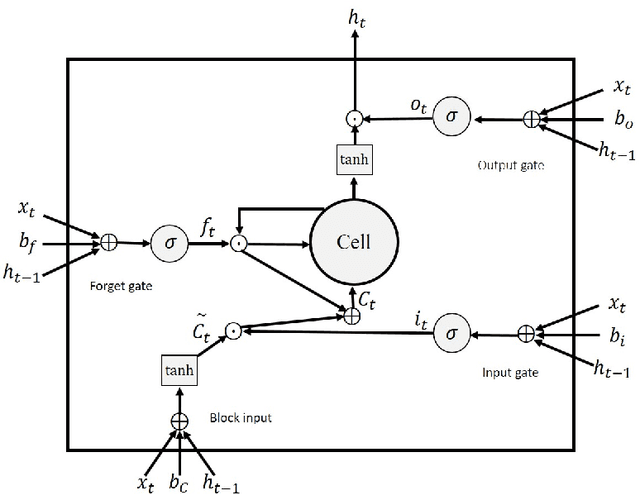
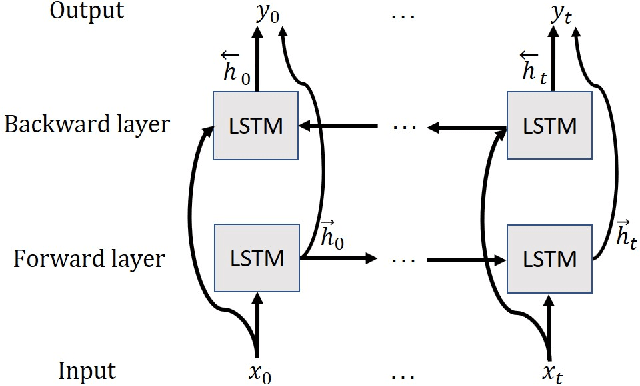
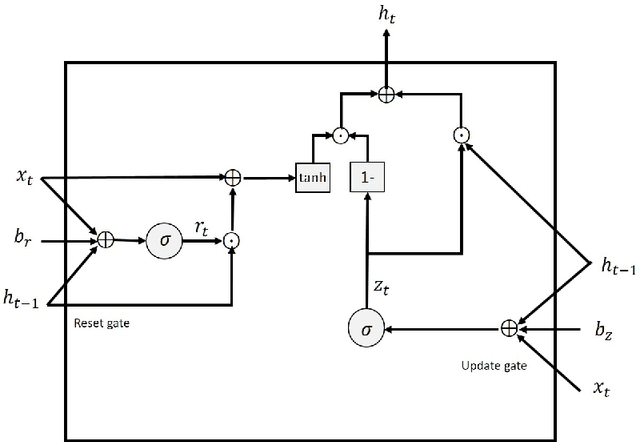
Log messages are now widely used in software systems. They are important for classification as millions of logs are generated each day. Most logs are unstructured which makes classification a challenge. In this paper, Deep Learning (DL) methods called Auto-LSTM, Auto-BLSTM and Auto-GRU are developed for anomaly detection and log classification. These models are used to convert unstructured log data to trained features which is suitable for classification algorithms. They are evaluated using four data sets, namely BGL, Openstack, Thunderbird and IMDB. The first three are popular log data sets while the fourth is a movie review data set which is used for sentiment classification and is used here to show that the models can be generalized to other text classification tasks. The results obtained show that Auto-LSTM, Auto-BLSTM and Auto-GRU perform better than other well-known algorithms.
Predicting the Programming Language of Questions and Snippets of StackOverflow Using Natural Language Processing
Sep 21, 2018



Stack Overflow is the most popular Q&A website among software developers. As a platform for knowledge sharing and acquisition, the questions posted in Stack Overflow usually contain a code snippet. Stack Overflow relies on users to properly tag the programming language of a question and it simply assumes that the programming language of the snippets inside a question is the same as the tag of the question itself. In this paper, we propose a classifier to predict the programming language of questions posted in Stack Overflow using Natural Language Processing (NLP) and Machine Learning (ML). The classifier achieves an accuracy of 91.1% in predicting the 24 most popular programming languages by combining features from the title, body and the code snippets of the question. We also propose a classifier that only uses the title and body of the question and has an accuracy of 81.1%. Finally, we propose a classifier of code snippets only that achieves an accuracy of 77.7%. These results show that deploying Machine Learning techniques on the combination of text and the code snippets of a question provides the best performance. These results demonstrate also that it is possible to identify the programming language of a snippet of few lines of source code. We visualize the feature space of two programming languages Java and SQL in order to identify some special properties of information inside the questions in Stack Overflow corresponding to these languages.
SCC: Automatic Classification of Code Snippets
Sep 21, 2018



Determining the programming language of a source code file has been considered in the research community; it has been shown that Machine Learning (ML) and Natural Language Processing (NLP) algorithms can be effective in identifying the programming language of source code files. However, determining the programming language of a code snippet or a few lines of source code is still a challenging task. Online forums such as Stack Overflow and code repositories such as GitHub contain a large number of code snippets. In this paper, we describe Source Code Classification (SCC), a classifier that can identify the programming language of code snippets written in 21 different programming languages. A Multinomial Naive Bayes (MNB) classifier is employed which is trained using Stack Overflow posts. It is shown to achieve an accuracy of 75% which is higher than that with Programming Languages Identification (PLI a proprietary online classifier of snippets) whose accuracy is only 55.5%. The average score for precision, recall and the F1 score with the proposed tool are 0.76, 0.75 and 0.75, respectively. In addition, it can distinguish between code snippets from a family of programming languages such as C, C++ and C#, and can also identify the programming language version such as C# 3.0, C# 4.0 and C# 5.0.