 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOversampling Log Messages Using a Sequence Generative Adversarial Network for Anomaly Detection and Classification
Jan 04, 2020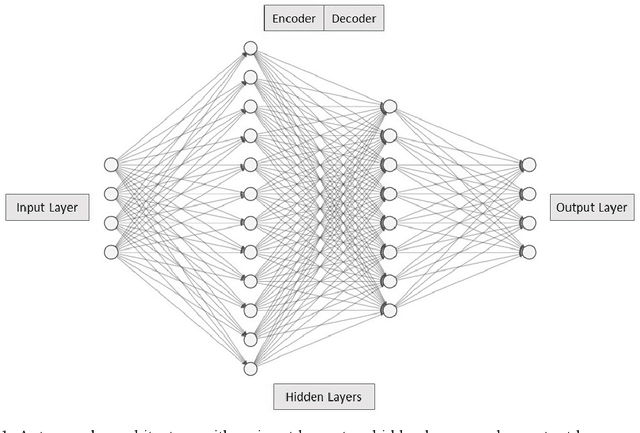
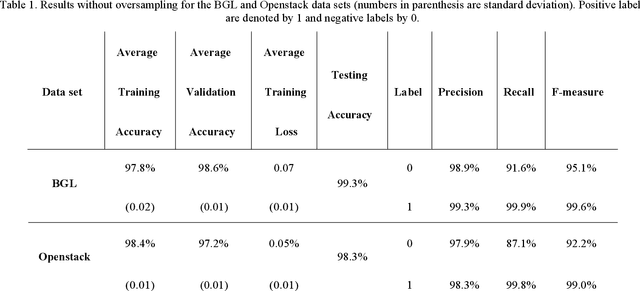
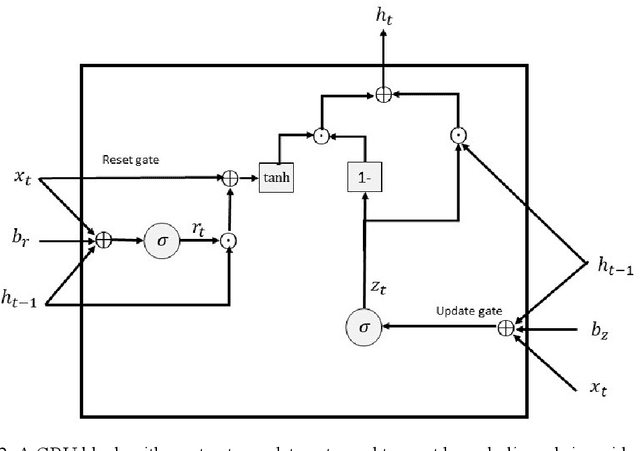
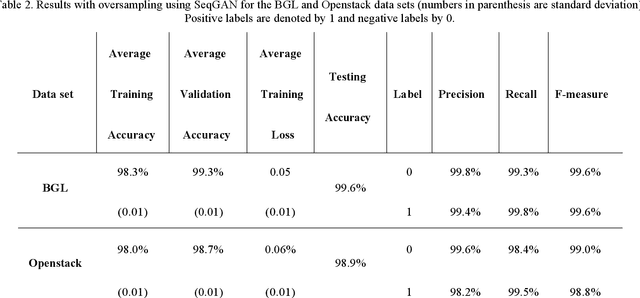
Dealing with imbalanced data is one of the main challenges in machine/deep learning algorithms for classification. This issue is more important with log message data as it is typically very imbalanced and negative logs are rare. In this paper, a model is proposed to generate text log messages using a SeqGAN network. Then features are extracted using an Autoencoder and anomaly detection is done using a GRU network. The proposed model is evaluated with two imbalanced log data sets, namely BGL and Openstack. Results are presented which show that oversampling and balancing data increases the accuracy of anomaly detection and classification.
Log Message Anomaly Detection and Classification Using Auto-B/LSTM and Auto-GRU
Nov 20, 2019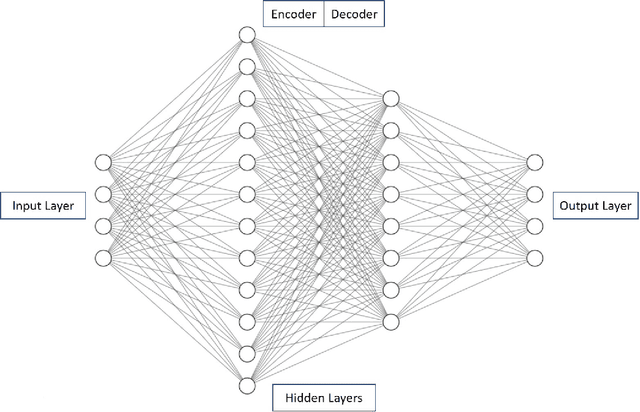
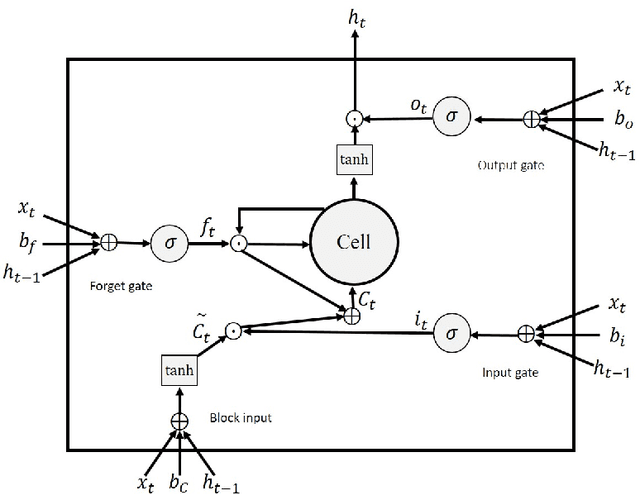
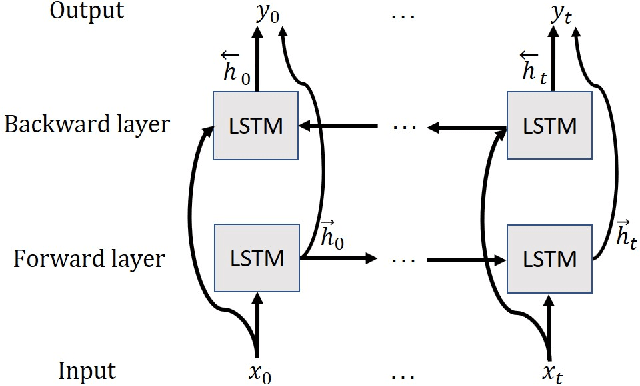
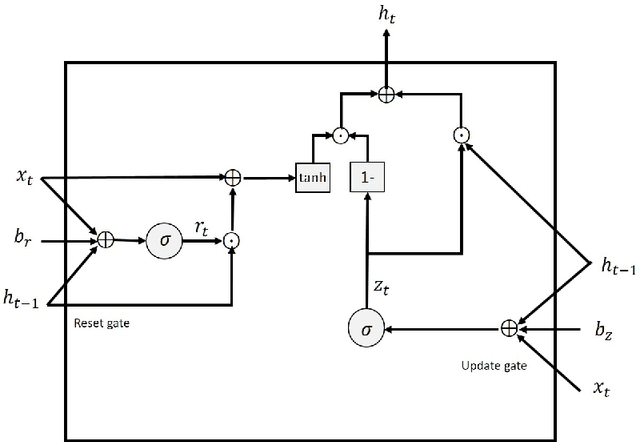
Log messages are now widely used in software systems. They are important for classification as millions of logs are generated each day. Most logs are unstructured which makes classification a challenge. In this paper, Deep Learning (DL) methods called Auto-LSTM, Auto-BLSTM and Auto-GRU are developed for anomaly detection and log classification. These models are used to convert unstructured log data to trained features which is suitable for classification algorithms. They are evaluated using four data sets, namely BGL, Openstack, Thunderbird and IMDB. The first three are popular log data sets while the fourth is a movie review data set which is used for sentiment classification and is used here to show that the models can be generalized to other text classification tasks. The results obtained show that Auto-LSTM, Auto-BLSTM and Auto-GRU perform better than other well-known algorithms.