 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOptimizing Keyphrase Ranking for Relevance and Diversity Using Submodular Function Optimization (SFO)
Oct 26, 2024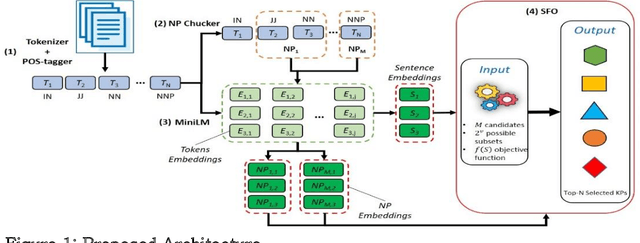
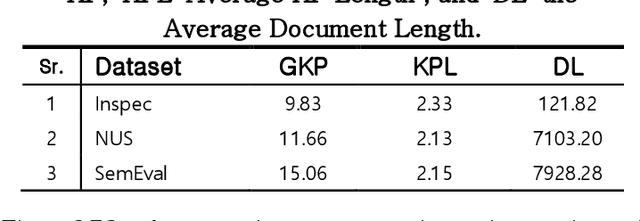
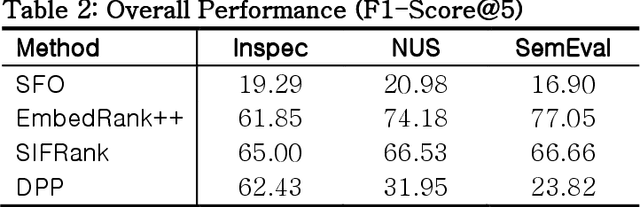

Keyphrase ranking plays a crucial role in information retrieval and summarization by indexing and retrieving relevant information efficiently. Advances in natural language processing, especially large language models (LLMs), have improved keyphrase extraction and ranking. However, traditional methods often overlook diversity, resulting in redundant keyphrases. We propose a novel approach using Submodular Function Optimization (SFO) to balance relevance and diversity in keyphrase ranking. By framing the task as submodular maximization, our method selects diverse and representative keyphrases. Experiments on benchmark datasets show that our approach outperforms existing methods in both relevance and diversity metrics, achieving SOTA performance in execution time. Our code is available online.