 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpatio-Temporal Attention and Gaussian Processes for Personalized Video Gaze Estimation
Apr 10, 2024



Gaze is an essential prompt for analyzing human behavior and attention. Recently, there has been an increasing interest in determining gaze direction from facial videos. However, video gaze estimation faces significant challenges, such as understanding the dynamic evolution of gaze in video sequences, dealing with static backgrounds, and adapting to variations in illumination. To address these challenges, we propose a simple and novel deep learning model designed to estimate gaze from videos, incorporating a specialized attention module. Our method employs a spatial attention mechanism that tracks spatial dynamics within videos. This technique enables accurate gaze direction prediction through a temporal sequence model, adeptly transforming spatial observations into temporal insights, thereby significantly improving gaze estimation accuracy. Additionally, our approach integrates Gaussian processes to include individual-specific traits, facilitating the personalization of our model with just a few labeled samples. Experimental results confirm the efficacy of the proposed approach, demonstrating its success in both within-dataset and cross-dataset settings. Specifically, our proposed approach achieves state-of-the-art performance on the Gaze360 dataset, improving by $2.5^\circ$ without personalization. Further, by personalizing the model with just three samples, we achieved an additional improvement of $0.8^\circ$. The code and pre-trained models are available at \url{https://github.com/jswati31/stage}.
Contrastive Representation Learning for Gaze Estimation
Oct 24, 2022Self-supervised learning (SSL) has become prevalent for learning representations in computer vision. Notably, SSL exploits contrastive learning to encourage visual representations to be invariant under various image transformations. The task of gaze estimation, on the other hand, demands not just invariance to various appearances but also equivariance to the geometric transformations. In this work, we propose a simple contrastive representation learning framework for gaze estimation, named Gaze Contrastive Learning (GazeCLR). GazeCLR exploits multi-view data to promote equivariance and relies on selected data augmentation techniques that do not alter gaze directions for invariance learning. Our experiments demonstrate the effectiveness of GazeCLR for several settings of the gaze estimation task. Particularly, our results show that GazeCLR improves the performance of cross-domain gaze estimation and yields as high as 17.2% relative improvement. Moreover, the GazeCLR framework is competitive with state-of-the-art representation learning methods for few-shot evaluation. The code and pre-trained models are available at https://github.com/jswati31/gazeclr.
CUDA-GR: Controllable Unsupervised Domain Adaptation for Gaze Redirection
Jun 21, 2021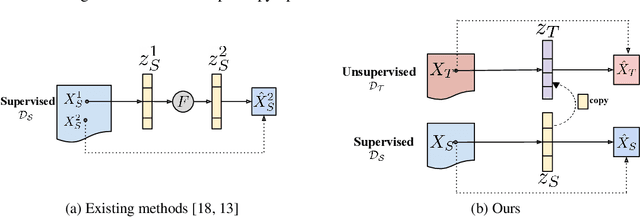
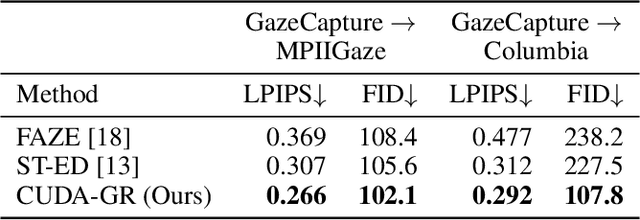
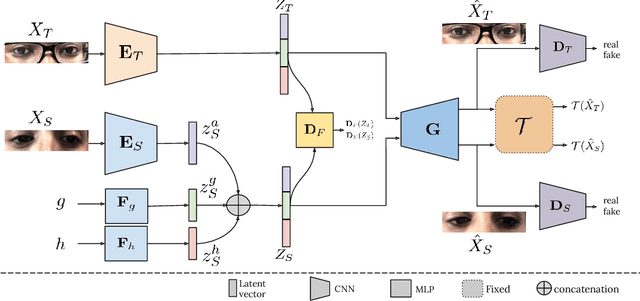

The aim of gaze redirection is to manipulate the gaze in an image to the desired direction. However, existing methods are inadequate in generating perceptually reasonable images. Advancement in generative adversarial networks has shown excellent results in generating photo-realistic images. Though, they still lack the ability to provide finer control over different image attributes. To enable such fine-tuned control, one needs to obtain ground truth annotations for the training data which can be very expensive. In this paper, we propose an unsupervised domain adaptation framework, called CUDA-GR, that learns to disentangle gaze representations from the labeled source domain and transfers them to an unlabeled target domain. Our method enables fine-grained control over gaze directions while preserving the appearance information of the person. We show that the generated image-labels pairs in the target domain are effective in knowledge transfer and can boost the performance of the downstream tasks. Extensive experiments on the benchmarking datasets show that the proposed method can outperform state-of-the-art techniques in both quantitative and qualitative evaluation.