 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAccurate Pedestrian Tracking in Urban Canyons: A Multi-Modal Fusion Approach
Jan 29, 2026The contribution describes a pedestrian navigation approach designed to improve localization accuracy in urban environments where GNSS performance is degraded, a problem that is especially critical for blind or low-vision users who depend on precise guidance such as identifying the correct side of a street. To address GNSS limitations and the impracticality of camera-based visual positioning, the work proposes a particle filter based fusion of GNSS and inertial data that incorporates spatial priors from maps, such as impassable buildings and unlikely walking areas, functioning as a probabilistic form of map matching. Inertial localization is provided by the RoNIN machine learning method, and fusion with GNSS is achieved by weighting particles based on their consistency with GNSS estimates and uncertainty. The system was evaluated on six challenging walking routes in downtown San Francisco using three metrics related to sidewalk correctness and localization error. Results show that the fused approach (GNSS+RoNIN+PF) significantly outperforms GNSS only localization on most metrics, while inertial-only localization with particle filtering also surpasses GNSS alone for critical measures such as sidewalk assignment and across street error.
PALMS+: Modular Image-Based Floor Plan Localization Leveraging Depth Foundation Model
Nov 12, 2025Indoor localization in GPS-denied environments is crucial for applications like emergency response and assistive navigation. Vision-based methods such as PALMS enable infrastructure-free localization using only a floor plan and a stationary scan, but are limited by the short range of smartphone LiDAR and ambiguity in indoor layouts. We propose PALMS$+$, a modular, image-based system that addresses these challenges by reconstructing scale-aligned 3D point clouds from posed RGB images using a foundation monocular depth estimation model (Depth Pro), followed by geometric layout matching via convolution with the floor plan. PALMS$+$ outputs a posterior over the location and orientation, usable for direct or sequential localization. Evaluated on the Structured3D and a custom campus dataset consisting of 80 observations across four large campus buildings, PALMS$+$ outperforms PALMS and F3Loc in stationary localization accuracy -- without requiring any training. Furthermore, when integrated with a particle filter for sequential localization on 33 real-world trajectories, PALMS$+$ achieved lower localization errors compared to other methods, demonstrating robustness for camera-free tracking and its potential for infrastructure-free applications. Code and data are available at https://github.com/Head-inthe-Cloud/PALMS-Plane-based-Accessible-Indoor-Localization-Using-Mobile-Smartphones
PALMS: Plane-based Accessible Indoor Localization Using Mobile Smartphones
Oct 21, 2024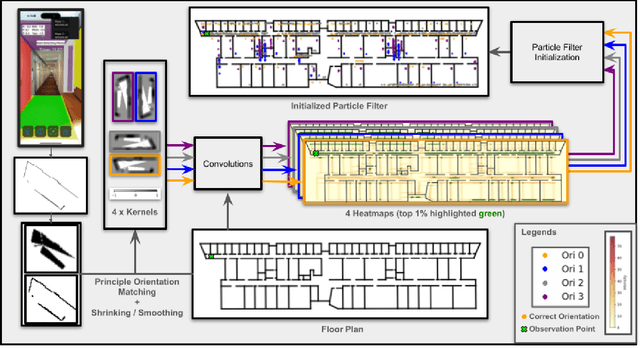
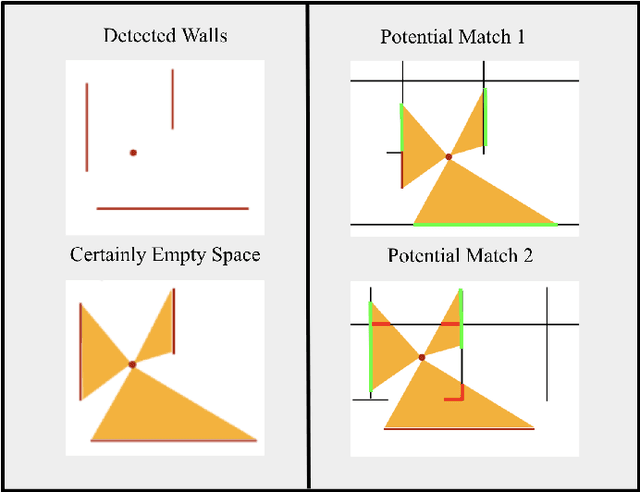
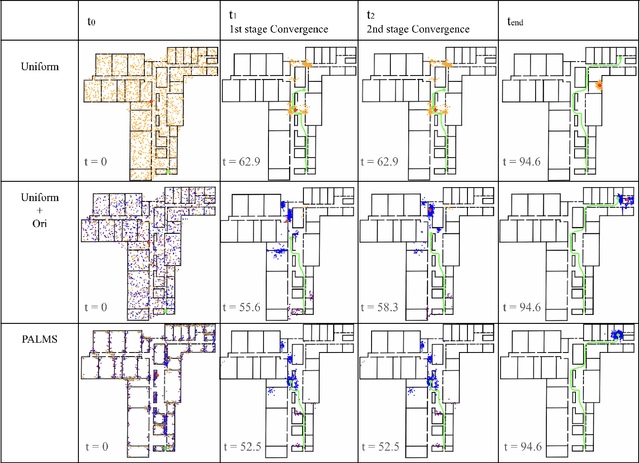

In this paper, we present PALMS, an innovative indoor global localization and relocalization system for mobile smartphones that utilizes publicly available floor plans. Unlike most vision-based methods that require constant visual input, our system adopts a dynamic form of localization that considers a single instantaneous observation and odometry data. The core contribution of this work is the introduction of a particle filter initialization method that leverages the Certainly Empty Space (CES) constraint along with principal orientation matching. This approach creates a spatial probability distribution of the device's location, significantly improving localization accuracy and reducing particle filter convergence time. Our experimental evaluations demonstrate that PALMS outperforms traditional methods with uniformly initialized particle filters, providing a more efficient and accessible approach to indoor wayfinding. By eliminating the need for prior environmental fingerprinting, PALMS provides a scalable and practical approach to indoor navigation.
Spatio-Temporal Attention and Gaussian Processes for Personalized Video Gaze Estimation
Apr 10, 2024



Gaze is an essential prompt for analyzing human behavior and attention. Recently, there has been an increasing interest in determining gaze direction from facial videos. However, video gaze estimation faces significant challenges, such as understanding the dynamic evolution of gaze in video sequences, dealing with static backgrounds, and adapting to variations in illumination. To address these challenges, we propose a simple and novel deep learning model designed to estimate gaze from videos, incorporating a specialized attention module. Our method employs a spatial attention mechanism that tracks spatial dynamics within videos. This technique enables accurate gaze direction prediction through a temporal sequence model, adeptly transforming spatial observations into temporal insights, thereby significantly improving gaze estimation accuracy. Additionally, our approach integrates Gaussian processes to include individual-specific traits, facilitating the personalization of our model with just a few labeled samples. Experimental results confirm the efficacy of the proposed approach, demonstrating its success in both within-dataset and cross-dataset settings. Specifically, our proposed approach achieves state-of-the-art performance on the Gaze360 dataset, improving by $2.5^\circ$ without personalization. Further, by personalizing the model with just three samples, we achieved an additional improvement of $0.8^\circ$. The code and pre-trained models are available at \url{https://github.com/jswati31/stage}.
Contrastive Representation Learning for Gaze Estimation
Oct 24, 2022Self-supervised learning (SSL) has become prevalent for learning representations in computer vision. Notably, SSL exploits contrastive learning to encourage visual representations to be invariant under various image transformations. The task of gaze estimation, on the other hand, demands not just invariance to various appearances but also equivariance to the geometric transformations. In this work, we propose a simple contrastive representation learning framework for gaze estimation, named Gaze Contrastive Learning (GazeCLR). GazeCLR exploits multi-view data to promote equivariance and relies on selected data augmentation techniques that do not alter gaze directions for invariance learning. Our experiments demonstrate the effectiveness of GazeCLR for several settings of the gaze estimation task. Particularly, our results show that GazeCLR improves the performance of cross-domain gaze estimation and yields as high as 17.2% relative improvement. Moreover, the GazeCLR framework is competitive with state-of-the-art representation learning methods for few-shot evaluation. The code and pre-trained models are available at https://github.com/jswati31/gazeclr.
Automatic Semantic Content Removal by Learning to Neglect
Jul 20, 2018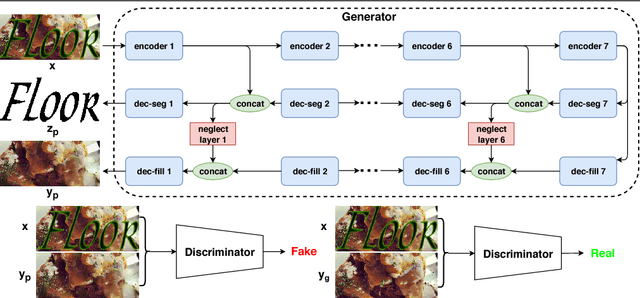
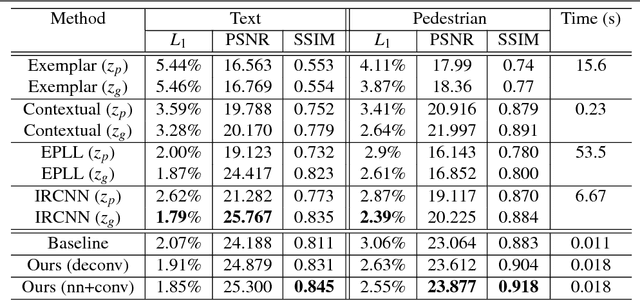


We introduce a new system for automatic image content removal and inpainting. Unlike traditional inpainting algorithms, which require advance knowledge of the region to be filled in, our system automatically detects the area to be removed and infilled. Region segmentation and inpainting are performed jointly in a single pass. In this way, potential segmentation errors are more naturally alleviated by the inpainting module. The system is implemented as an encoder-decoder architecture, with two decoder branches, one tasked with segmentation of the foreground region, the other with inpainting. The encoder and the two decoder branches are linked via neglect nodes, which guide the inpainting process in selecting which areas need reconstruction. The whole model is trained using a conditional GAN strategy. Comparative experiments show that our algorithm outperforms state-of-the-art inpainting techniques (which, unlike our system, do not segment the input image and thus must be aided by an external segmentation module.)
Cascaded Segmentation-Detection Networks for Word-Level Text Spotting
Apr 03, 2017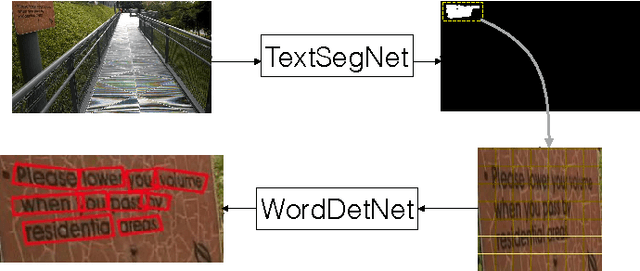


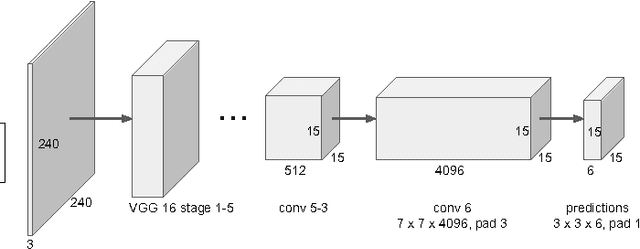
We introduce an algorithm for word-level text spotting that is able to accurately and reliably determine the bounding regions of individual words of text "in the wild". Our system is formed by the cascade of two convolutional neural networks. The first network is fully convolutional and is in charge of detecting areas containing text. This results in a very reliable but possibly inaccurate segmentation of the input image. The second network (inspired by the popular YOLO architecture) analyzes each segment produced in the first stage, and predicts oriented rectangular regions containing individual words. No post-processing (e.g. text line grouping) is necessary. With execution time of 450 ms for a 1000-by-560 image on a Titan X GPU, our system achieves the highest score to date among published algorithms on the ICDAR 2015 Incidental Scene Text dataset benchmark.