 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCascaded Segmentation-Detection Networks for Word-Level Text Spotting
Paper and Code
Apr 03, 2017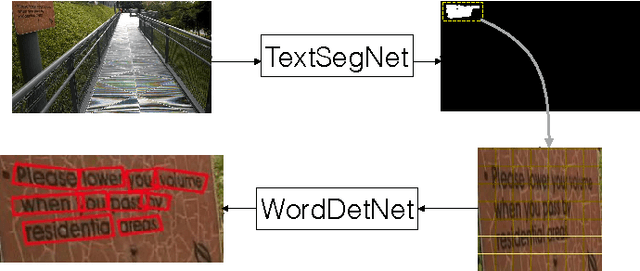


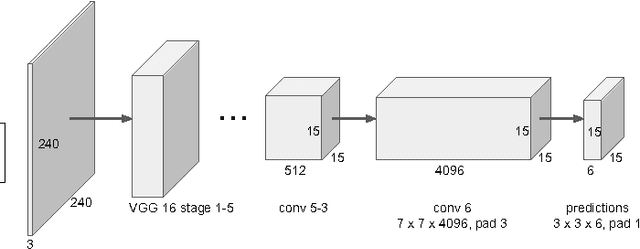
We introduce an algorithm for word-level text spotting that is able to accurately and reliably determine the bounding regions of individual words of text "in the wild". Our system is formed by the cascade of two convolutional neural networks. The first network is fully convolutional and is in charge of detecting areas containing text. This results in a very reliable but possibly inaccurate segmentation of the input image. The second network (inspired by the popular YOLO architecture) analyzes each segment produced in the first stage, and predicts oriented rectangular regions containing individual words. No post-processing (e.g. text line grouping) is necessary. With execution time of 450 ms for a 1000-by-560 image on a Titan X GPU, our system achieves the highest score to date among published algorithms on the ICDAR 2015 Incidental Scene Text dataset benchmark.