 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCUDA-GR: Controllable Unsupervised Domain Adaptation for Gaze Redirection
Paper and Code
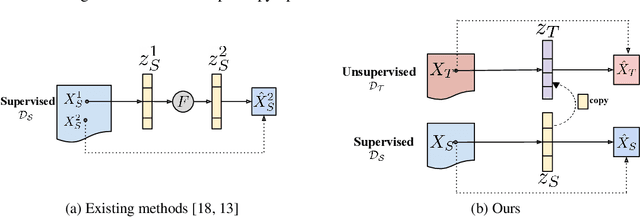
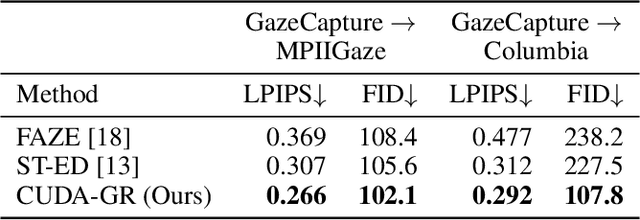
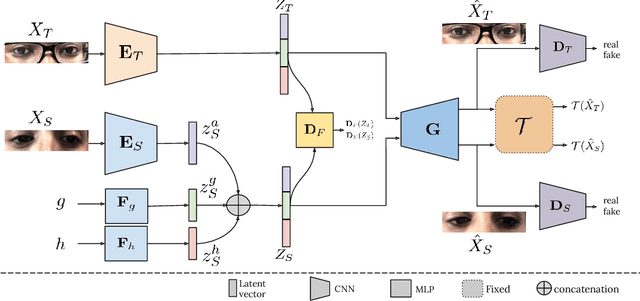

The aim of gaze redirection is to manipulate the gaze in an image to the desired direction. However, existing methods are inadequate in generating perceptually reasonable images. Advancement in generative adversarial networks has shown excellent results in generating photo-realistic images. Though, they still lack the ability to provide finer control over different image attributes. To enable such fine-tuned control, one needs to obtain ground truth annotations for the training data which can be very expensive. In this paper, we propose an unsupervised domain adaptation framework, called CUDA-GR, that learns to disentangle gaze representations from the labeled source domain and transfers them to an unlabeled target domain. Our method enables fine-grained control over gaze directions while preserving the appearance information of the person. We show that the generated image-labels pairs in the target domain are effective in knowledge transfer and can boost the performance of the downstream tasks. Extensive experiments on the benchmarking datasets show that the proposed method can outperform state-of-the-art techniques in both quantitative and qualitative evaluation.