 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Survey on Online User Aggression: Content Detection and Behavioural Analysis on Social Media Platforms
Nov 15, 2023The rise of social media platforms has led to an increase in cyber-aggressive behavior, encompassing a broad spectrum of hostile behavior, including cyberbullying, online harassment, and the dissemination of offensive and hate speech. These behaviors have been associated with significant societal consequences, ranging from online anonymity to real-world outcomes such as depression, suicidal tendencies, and, in some instances, offline violence. Recognizing the societal risks associated with unchecked aggressive content, this paper delves into the field of Aggression Content Detection and Behavioral Analysis of Aggressive Users, aiming to bridge the gap between disparate studies. In this paper, we analyzed the diversity of definitions and proposed a unified cyber-aggression definition. We examine the comprehensive process of Aggression Content Detection, spanning from dataset creation, feature selection and extraction, and detection algorithm development. Further, we review studies on Behavioral Analysis of Aggression that explore the influencing factors, consequences, and patterns associated with cyber-aggressive behavior. This systematic literature review is a cross-examination of content detection and behavioral analysis in the realm of cyber-aggression. The integrated investigation reveals the effectiveness of incorporating sociological insights into computational techniques for preventing cyber-aggressive behavior. Finally, the paper concludes by identifying research gaps and encouraging further progress in the unified domain of socio-computational aggressive behavior analysis.
Researchers eye-view of sarcasm detection in social media textual content
Apr 17, 2023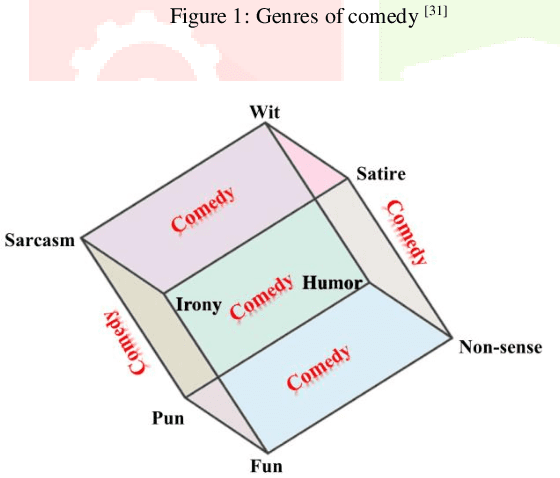
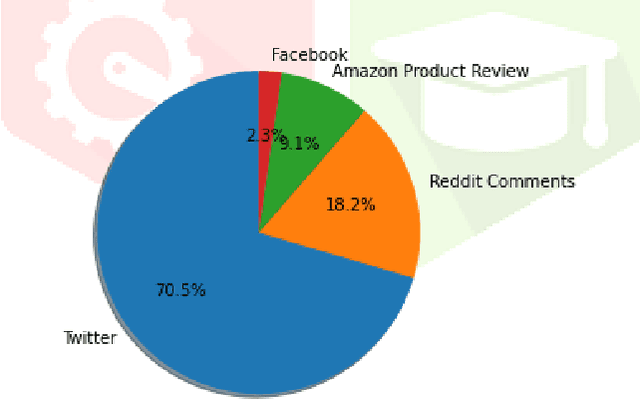
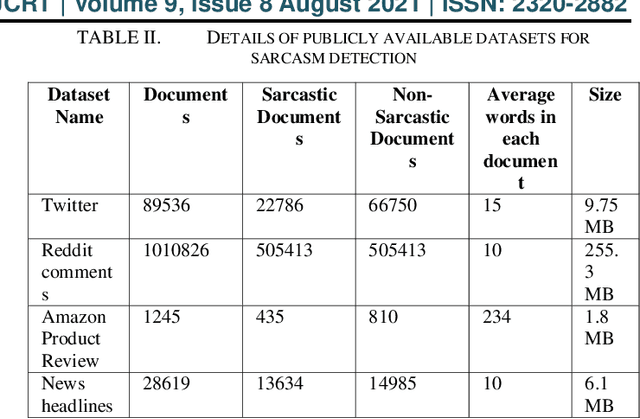
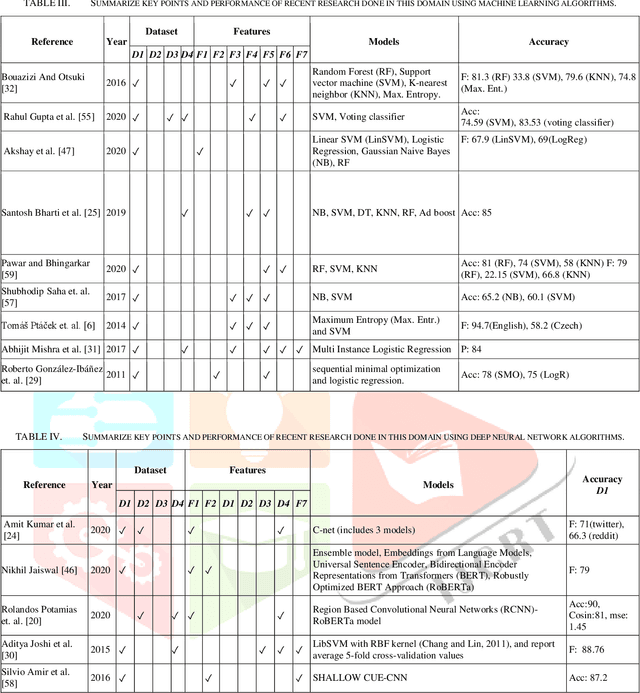
The enormous use of sarcastic text in all forms of communication in social media will have a physiological effect on target users. Each user has a different approach to misusing and recognising sarcasm. Sarcasm detection is difficult even for users, and this will depend on many things such as perspective, context, special symbols. So, that will be a challenging task for machines to differentiate sarcastic sentences from non-sarcastic sentences. There are no exact rules based on which model will accurately detect sarcasm from many text corpus in the current situation. So, one needs to focus on optimistic and forthcoming approaches in the sarcasm detection domain. This paper discusses various sarcasm detection techniques and concludes with some approaches, related datasets with optimal features, and the researcher's challenges.
* 8 pages
Thematic context vector association based on event uncertainty for Twitter
Apr 04, 2023



Keyword extraction is a crucial process in text mining. The extraction of keywords with respective contextual events in Twitter data is a big challenge. The challenging issues are mainly because of the informality in the language used. The use of misspelled words, acronyms, and ambiguous terms causes informality. The extraction of keywords with informal language in current systems is pattern based or event based. In this paper, contextual keywords are extracted using thematic events with the help of data association. The thematic context for events is identified using the uncertainty principle in the proposed system. The thematic contexts are weighed with the help of vectors called thematic context vectors which signifies the event as certain or uncertain. The system is tested on the Twitter COVID-19 dataset and proves to be effective. The system extracts event-specific thematic context vectors from the test dataset and ranks them. The extracted thematic context vectors are used for the clustering of contextual thematic vectors which improves the silhouette coefficient by 0.5% than state of art methods namely TF and TF-IDF. The thematic context vector can be used in other applications like Cyberbullying, sarcasm detection, figurative language detection, etc.
Polarity based Sarcasm Detection using Semigraph
Apr 04, 2023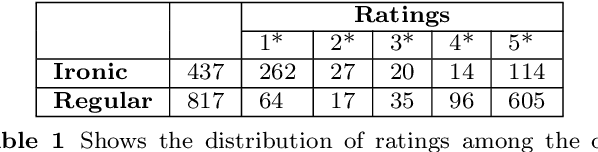
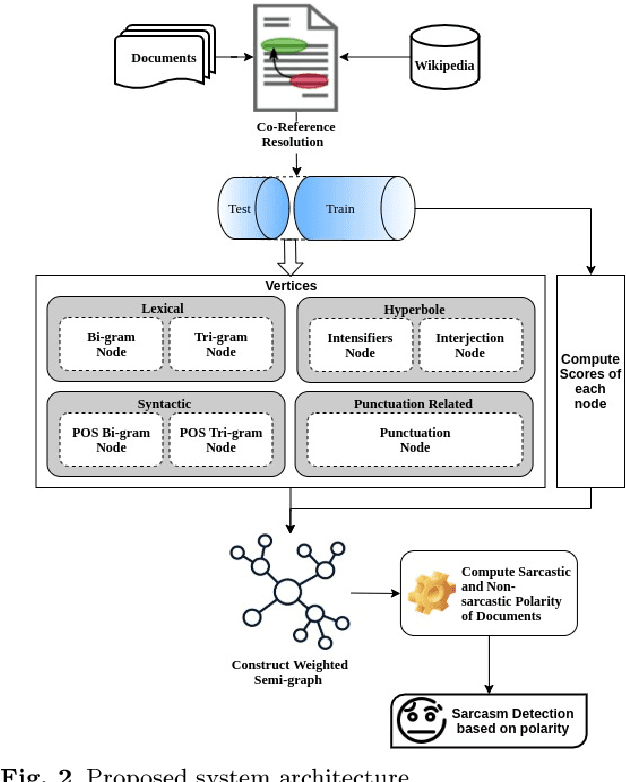

Sarcasm is an advanced linguistic expression often found on various online platforms. Sarcasm detection is challenging in natural language processing tasks that affect sentiment analysis. This article presents the inventive method of the semigraph, including semigraph construction and sarcasm detection processes. A variation of the semigraph is suggested in the pattern-relatedness of the text document. The proposed method is to obtain the sarcastic and non-sarcastic polarity scores of a document using a semigraph. The sarcastic polarity score represents the possibility that a document will become sarcastic. Sarcasm is detected based on the polarity scoring model. The performance of the proposed model enhances the existing prior art approach to sarcasm detection. In the Amazon product review, the model achieved the accuracy, recall, and f-measure of 0.87, 0.79, and 0.83, respectively.