 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThematic context vector association based on event uncertainty for Twitter
Apr 04, 2023



Keyword extraction is a crucial process in text mining. The extraction of keywords with respective contextual events in Twitter data is a big challenge. The challenging issues are mainly because of the informality in the language used. The use of misspelled words, acronyms, and ambiguous terms causes informality. The extraction of keywords with informal language in current systems is pattern based or event based. In this paper, contextual keywords are extracted using thematic events with the help of data association. The thematic context for events is identified using the uncertainty principle in the proposed system. The thematic contexts are weighed with the help of vectors called thematic context vectors which signifies the event as certain or uncertain. The system is tested on the Twitter COVID-19 dataset and proves to be effective. The system extracts event-specific thematic context vectors from the test dataset and ranks them. The extracted thematic context vectors are used for the clustering of contextual thematic vectors which improves the silhouette coefficient by 0.5% than state of art methods namely TF and TF-IDF. The thematic context vector can be used in other applications like Cyberbullying, sarcasm detection, figurative language detection, etc.
Contextual Mood Analysis with Knowledge Graph Representation for Hindi Song Lyrics in Devanagari Script
Aug 16, 2021

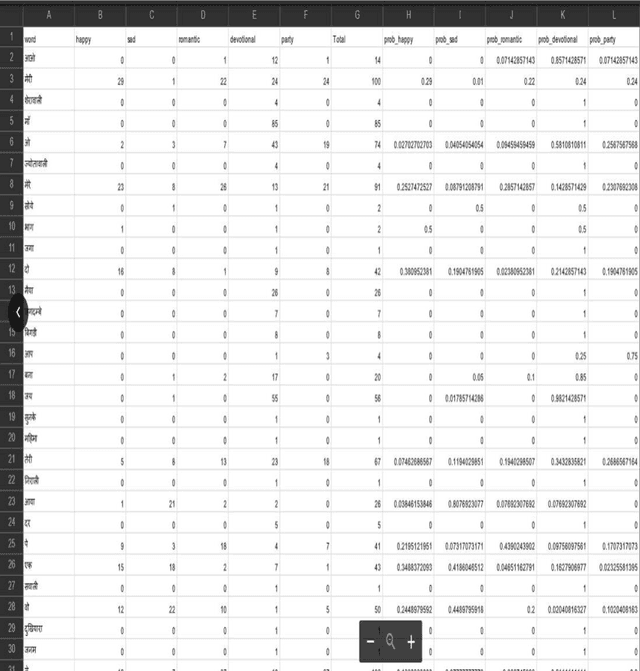

Lyrics play a significant role in conveying the song's mood and are information to understand and interpret music communication. Conventional natural language processing approaches use translation of the Hindi text into English for analysis. This approach is not suitable for lyrics as it is likely to lose the inherent intended contextual meaning. Thus, the need was identified to develop a system for Devanagari text analysis. The data set of 300 song lyrics with equal distribution in five different moods is used for the experimentation. The proposed system performs contextual mood analysis of Hindi song lyrics in Devanagari text format. The contextual analysis is stored as a knowledge base, updated using an incremental learning approach with new data. Contextual knowledge graph with moods and associated important contextual terms provides the graphical representation of the lyric data set used. The testing results show 64% accuracy for the mood prediction. This work can be easily extended to applications related to Hindi literary work such as summarization, indexing, contextual retrieval, context-based classification and grouping of documents.