 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSegmentation-free Connectionist Temporal Classification loss based OCR Model for Text Captcha Classification
Feb 08, 2024Captcha are widely used to secure systems from automatic responses by distinguishing computer responses from human responses. Text, audio, video, picture picture-based Optical Character Recognition (OCR) are used for creating captcha. Text-based OCR captcha are the most often used captcha which faces issues namely, complex and distorted contents. There are attempts to build captcha detection and classification-based systems using machine learning and neural networks, which need to be tuned for accuracy. The existing systems face challenges in the recognition of distorted characters, handling variable-length captcha and finding sequential dependencies in captcha. In this work, we propose a segmentation-free OCR model for text captcha classification based on the connectionist temporal classification loss technique. The proposed model is trained and tested on a publicly available captcha dataset. The proposed model gives 99.80\% character level accuracy, while 95\% word level accuracy. The accuracy of the proposed model is compared with the state-of-the-art models and proves to be effective. The variable length complex captcha can be thus processed with the segmentation-free connectionist temporal classification loss technique with dependencies which will be massively used in securing the software systems.
Contextual Mood Analysis with Knowledge Graph Representation for Hindi Song Lyrics in Devanagari Script
Aug 16, 2021

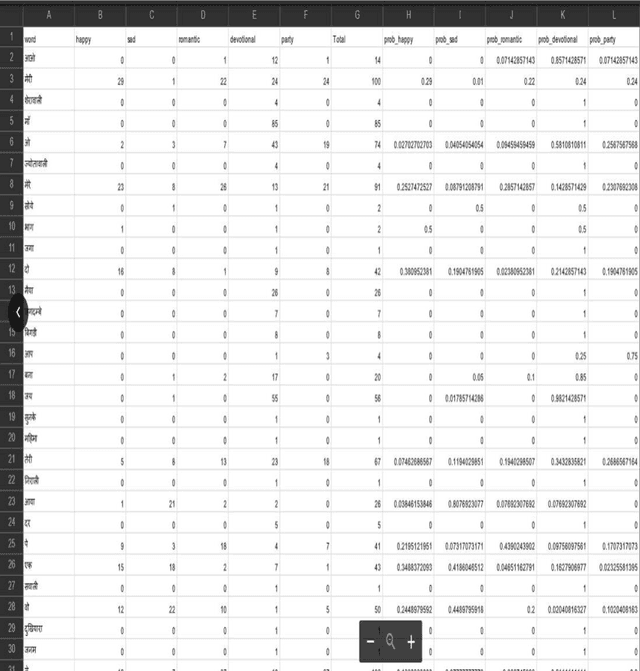

Lyrics play a significant role in conveying the song's mood and are information to understand and interpret music communication. Conventional natural language processing approaches use translation of the Hindi text into English for analysis. This approach is not suitable for lyrics as it is likely to lose the inherent intended contextual meaning. Thus, the need was identified to develop a system for Devanagari text analysis. The data set of 300 song lyrics with equal distribution in five different moods is used for the experimentation. The proposed system performs contextual mood analysis of Hindi song lyrics in Devanagari text format. The contextual analysis is stored as a knowledge base, updated using an incremental learning approach with new data. Contextual knowledge graph with moods and associated important contextual terms provides the graphical representation of the lyric data set used. The testing results show 64% accuracy for the mood prediction. This work can be easily extended to applications related to Hindi literary work such as summarization, indexing, contextual retrieval, context-based classification and grouping of documents.