 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOptimal Testing in the Experiment-rich Regime
May 30, 2018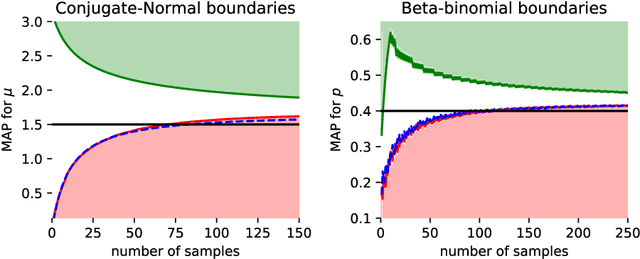
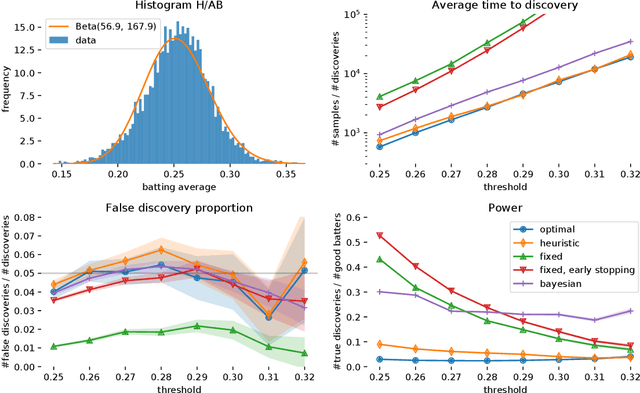
Motivated by the widespread adoption of large-scale A/B testing in industry, we propose a new experimentation framework for the setting where potential experiments are abundant (i.e., many hypotheses are available to test), and observations are costly; we refer to this as the experiment-rich regime. Such scenarios require the experimenter to internalize the opportunity cost of assigning a sample to a particular experiment. We fully characterize the optimal policy and give an algorithm to compute it. Furthermore, we develop a simple heuristic that also provides intuition for the optimal policy. We use simulations based on real data to compare both the optimal algorithm and the heuristic to other natural alternative experimental design frameworks. In particular, we discuss the paradox of power: high-powered classical tests can lead to highly inefficient sampling in the experiment-rich regime.
Human Interaction with Recommendation Systems
Mar 28, 2018
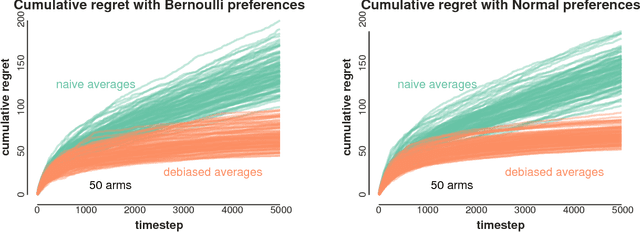
Many recommendation algorithms rely on user data to generate recommendations. However, these recommendations also affect the data obtained from future users. This work aims to understand the effects of this dynamic interaction. We propose a simple model where users with heterogeneous preferences arrive over time. Based on this model, we prove that naive estimators, i.e. those which ignore this feedback loop, are not consistent. We show that consistent estimators are efficient in the presence of myopic agents. Our results are validated using extensive simulations.
Learning with Abandonment
Feb 23, 2018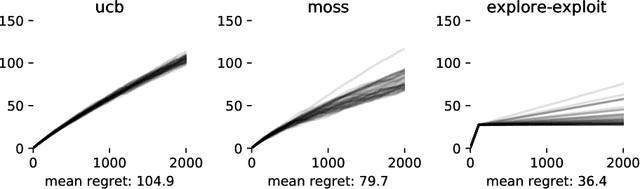


Consider a platform that wants to learn a personalized policy for each user, but the platform faces the risk of a user abandoning the platform if she is dissatisfied with the actions of the platform. For example, a platform is interested in personalizing the number of newsletters it sends, but faces the risk that the user unsubscribes forever. We propose a general thresholded learning model for scenarios like this, and discuss the structure of optimal policies. We describe salient features of optimal personalization algorithms and how feedback the platform receives impacts the results. Furthermore, we investigate how the platform can efficiently learn the heterogeneity across users by interacting with a population and provide performance guarantees.