 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInformation-theoretic Interestingness Measures for Cross-Ontology Data Mining
May 16, 2016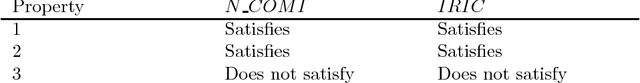
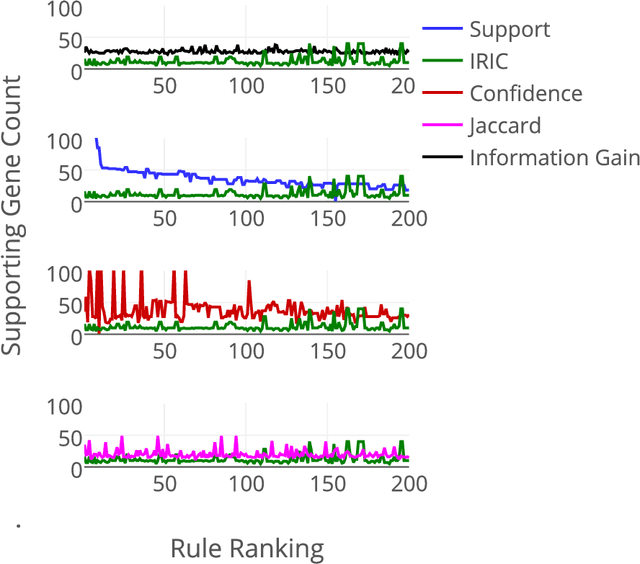
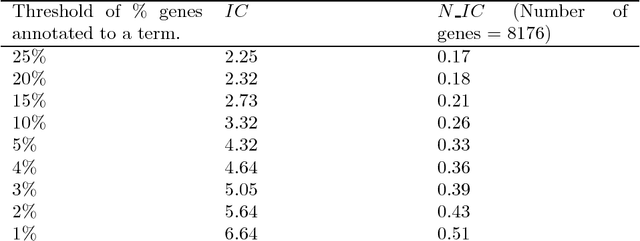
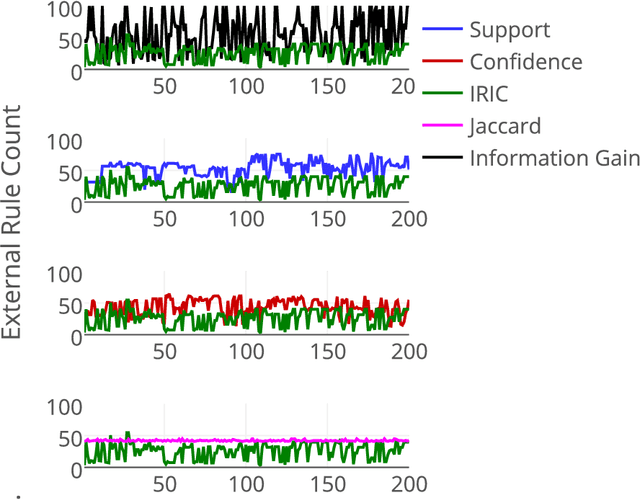
Community annotation of biological entities with concepts from multiple bio-ontologies has created large and growing repositories of ontology-based annotation data with embedded implicit relationships among orthogonal ontologies. Development of efficient data mining methods and metrics to mine and assess the quality of the mined relationships has not kept pace with the growth of annotation data. In this study, we present a data mining method that uses ontology-guided generalization to discover relationships across ontologies along with a new interestingness metric based on information theory. We apply our data mining algorithm and interestingness measures to datasets from the Gene Expression Database at the Mouse Genome Informatics as a preliminary proof of concept to mine relationships between developmental stages in the mouse anatomy ontology and Gene Ontology concepts (biological process, molecular function and cellular component). In addition, we present a comparison of our interestingness metric to four existing metrics. Ontology-based annotation datasets provide a valuable resource for discovery of relationships across ontologies. The use of efficient data mining methods and appropriate interestingness metrics enables the identification of high quality relationships.