 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMitigating Mismatch within Reference-based Preference Optimization
Feb 12, 2026Direct Preference Optimization (DPO) has become the de facto standard for offline preference alignment of large language models, but its reliance on a reference policy introduces a critical tension. DPO weighs each update relative to a reference, which stabilizes the training by regularizing the updates within a trusted region. This reliance becomes problematic for pessimistic pairs, where the reference model prefers the rejected response. For these pairs, DPO prematurely attenuates the gradient as soon as the policy margin ($Δ_θ$) merely beats the reference margin ($Δ_{\mathrm{ref}}$) even if the policy is still wrong ($Δ_θ<0$). We name this failure premature satisfaction, which is a concrete form of the training-inference mismatch. Reference-free objectives remove this mismatch by optimizing the absolute margin, but at the cost of discarding the stabilizing signal of the reference. We mitigate this tension with Hybrid-DPO (HyPO), a drop-in modification to DPO that applies reference conditionally: HyPO behaves exactly like DPO when the reference is optimistic or neutral, and it treats the reference as neutral when it is pessimistic by replacing $Δ_θ-Δ_{\mathrm{ref}}$ with $Δ_θ-\max\{0,Δ_{\mathrm{ref}}\}$. This one-line change strictly strengthens per-example learning signals on pessimistic pairs while preserving DPO's objective form and computational cost. By conditionally debiasing the pessimistic reference signal, HyPO mitigates premature satisfaction; empirically, across preference alignment, HyPO improves inference-aligned metrics and achieves higher pairwise win rates. Our results provide evidence that direct preference alignment could be enhanced by conditionally debiasing the reference signal, rather than discarding it.
Enhancing Sample Selection by Cutting Mislabeled Easy Examples
Feb 12, 2025Sample selection is a prevalent approach in learning with noisy labels, aiming to identify confident samples for training. Although existing sample selection methods have achieved decent results by reducing the noise rate of the selected subset, they often overlook that not all mislabeled examples harm the model's performance equally. In this paper, we demonstrate that mislabeled examples correctly predicted by the model early in the training process are particularly harmful to model performance. We refer to these examples as Mislabeled Easy Examples (MEEs). To address this, we propose Early Cutting, which introduces a recalibration step that employs the model's later training state to re-select the confident subset identified early in training, thereby avoiding misleading confidence from early learning and effectively filtering out MEEs. Experiments on the CIFAR, WebVision, and full ImageNet-1k datasets demonstrate that our method effectively improves sample selection and model performance by reducing MEEs.
Early Stopping Against Label Noise Without Validation Data
Feb 11, 2025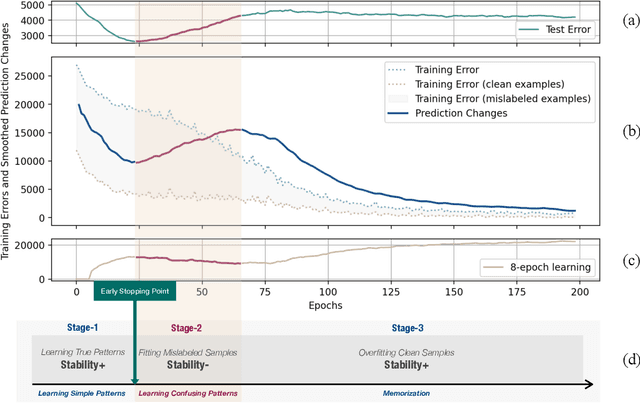
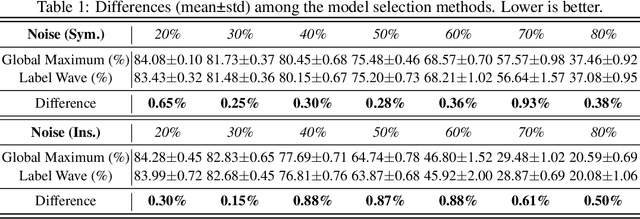
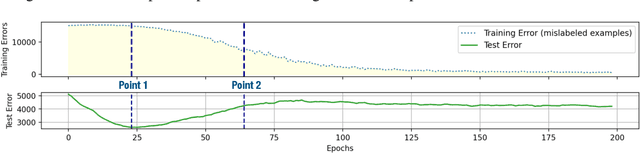

Early stopping methods in deep learning face the challenge of balancing the volume of training and validation data, especially in the presence of label noise. Concretely, sparing more data for validation from training data would limit the performance of the learned model, yet insufficient validation data could result in a sub-optimal selection of the desired model. In this paper, we propose a novel early stopping method called Label Wave, which does not require validation data for selecting the desired model in the presence of label noise. It works by tracking the changes in the model's predictions on the training set during the training process, aiming to halt training before the model unduly fits mislabeled data. This method is empirically supported by our observation that minimum fluctuations in predictions typically occur at the training epoch before the model excessively fits mislabeled data. Through extensive experiments, we show both the effectiveness of the Label Wave method across various settings and its capability to enhance the performance of existing methods for learning with noisy labels.
Instance-dependent Early Stopping
Feb 11, 2025In machine learning practice, early stopping has been widely used to regularize models and can save computational costs by halting the training process when the model's performance on a validation set stops improving. However, conventional early stopping applies the same stopping criterion to all instances without considering their individual learning statuses, which leads to redundant computations on instances that are already well-learned. To further improve the efficiency, we propose an Instance-dependent Early Stopping (IES) method that adapts the early stopping mechanism from the entire training set to the instance level, based on the core principle that once the model has mastered an instance, the training on it should stop. IES considers an instance as mastered if the second-order differences of its loss value remain within a small range around zero. This offers a more consistent measure of an instance's learning status compared with directly using the loss value, and thus allows for a unified threshold to determine when an instance can be excluded from further backpropagation. We show that excluding mastered instances from backpropagation can increase the gradient norms, thereby accelerating the decrease of the training loss and speeding up the training process. Extensive experiments on benchmarks demonstrate that IES method can reduce backpropagation instances by 10%-50% while maintaining or even slightly improving the test accuracy and transfer learning performance of a model.
Late Stopping: Avoiding Confidently Learning from Mislabeled Examples
Aug 26, 2023



Sample selection is a prevalent method in learning with noisy labels, where small-loss data are typically considered as correctly labeled data. However, this method may not effectively identify clean hard examples with large losses, which are critical for achieving the model's close-to-optimal generalization performance. In this paper, we propose a new framework, Late Stopping, which leverages the intrinsic robust learning ability of DNNs through a prolonged training process. Specifically, Late Stopping gradually shrinks the noisy dataset by removing high-probability mislabeled examples while retaining the majority of clean hard examples in the training set throughout the learning process. We empirically observe that mislabeled and clean examples exhibit differences in the number of epochs required for them to be consistently and correctly classified, and thus high-probability mislabeled examples can be removed. Experimental results on benchmark-simulated and real-world noisy datasets demonstrate that the proposed method outperforms state-of-the-art counterparts.