 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDetection of Propaganda Techniques in Visuo-Lingual Metaphor in Memes
May 03, 2022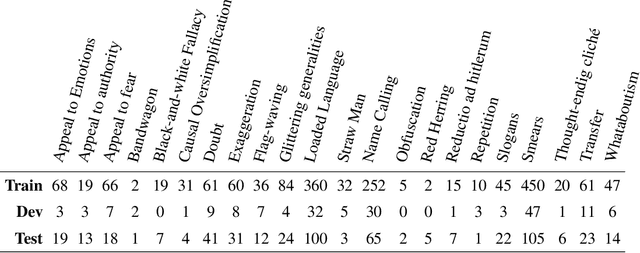
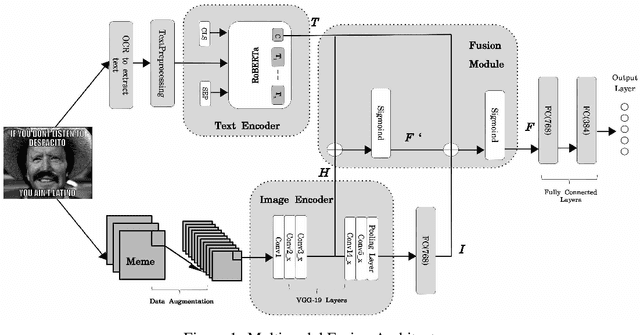


The exponential rise of social media networks has allowed the production, distribution, and consumption of data at a phenomenal rate. Moreover, the social media revolution has brought a unique phenomenon to social media platforms called Internet memes. Internet memes are one of the most popular contents used on social media, and they can be in the form of images with a witty, catchy, or satirical text description. In this paper, we are dealing with propaganda that is often seen in Internet memes in recent times. Propaganda is communication, which frequently includes psychological and rhetorical techniques to manipulate or influence an audience to act or respond as the propagandist wants. To detect propaganda in Internet memes, we propose a multimodal deep learning fusion system that fuses the text and image feature representations and outperforms individual models based solely on either text or image modalities.
Multichannel LSTM-CNN for Telugu Technical Domain Identification
Feb 24, 2021
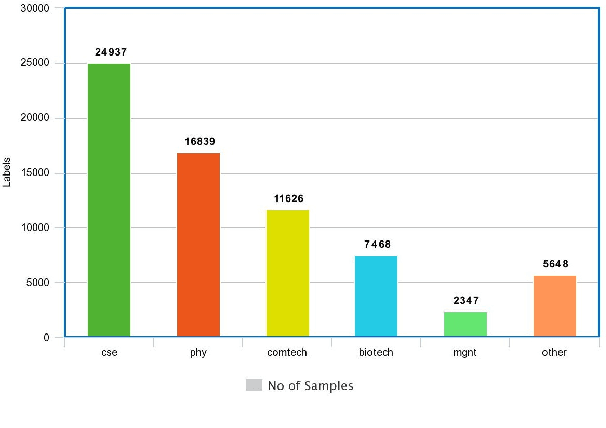
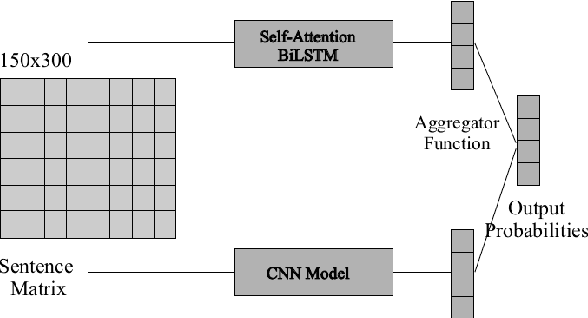

With the instantaneous growth of text information, retrieving domain-oriented information from the text data has a broad range of applications in Information Retrieval and Natural language Processing. Thematic keywords give a compressed representation of the text. Usually, Domain Identification plays a significant role in Machine Translation, Text Summarization, Question Answering, Information Extraction, and Sentiment Analysis. In this paper, we proposed the Multichannel LSTM-CNN methodology for Technical Domain Identification for Telugu. This architecture was used and evaluated in the context of the ICON shared task TechDOfication 2020 (task h), and our system got 69.9% of the F1 score on the test dataset and 90.01% on the validation set.
Transformer based Automatic COVID-19 Fake News Detection System
Jan 21, 2021

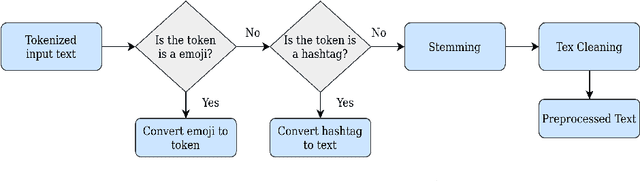

Recent rapid technological advancements in online social networks such as Twitter have led to a great incline in spreading false information and fake news. Misinformation is especially prevalent in the ongoing coronavirus disease (COVID-19) pandemic, leading to individuals accepting bogus and potentially deleterious claims and articles. Quick detection of fake news can reduce the spread of panic and confusion among the public. For our analysis in this paper, we report a methodology to analyze the reliability of information shared on social media pertaining to the COVID-19 pandemic. Our best approach is based on an ensemble of three transformer models (BERT, ALBERT, and XLNET) to detecting fake news. This model was trained and evaluated in the context of the ConstraintAI 2021 shared task COVID19 Fake News Detection in English. Our system obtained 0.9855 f1-score on testset and ranked 5th among 160 teams.
Word Level Language Identification in English Telugu Code Mixed Data
Oct 09, 2020
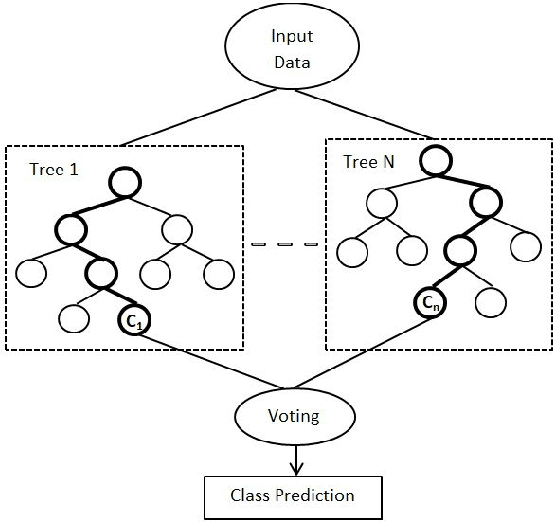
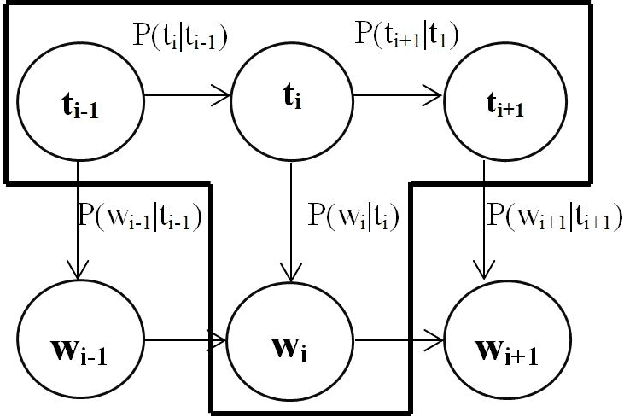

In a multilingual or sociolingual configuration Intra-sentential Code Switching (ICS) or Code Mixing (CM) is frequently observed nowadays. In the world, most of the people know more than one language. CM usage is especially apparent in social media platforms. Moreover, ICS is particularly significant in the context of technology, health, and law where conveying the upcoming developments are difficult in one's native language. In applications like dialog systems, machine translation, semantic parsing, shallow parsing, etc. CM and Code Switching pose serious challenges. To do any further advancement in code-mixed data, the necessary step is Language Identification. In this paper, we present a study of various models - Nave Bayes Classifier, Random Forest Classifier, Conditional Random Field (CRF), and Hidden Markov Model (HMM) for Language Identification in English - Telugu Code Mixed Data. Considering the paucity of resources in code mixed languages, we proposed the CRF model and HMM model for word level language identification. Our best performing system is CRF-based with an f1-score of 0.91.
gundapusunil at SemEval-2020 Task 8: Multimodal Memotion Analysis
Oct 09, 2020
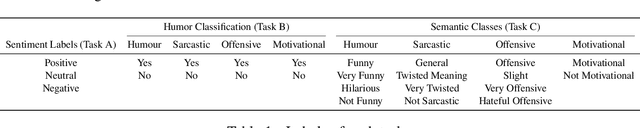

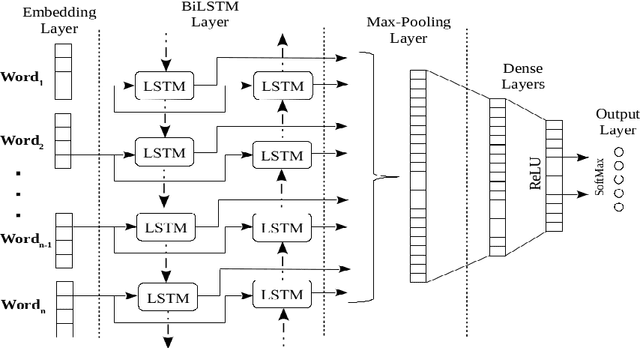
Recent technological advancements in the Internet and Social media usage have resulted in the evolution of faster and efficient platforms of communication. These platforms include visual, textual and speech mediums and have brought a unique social phenomenon called Internet memes. Internet memes are in the form of images with witty, catchy, or sarcastic text descriptions. In this paper, we present a multi-modal sentiment analysis system using deep neural networks combining Computer Vision and Natural Language Processing. Our aim is different than the normal sentiment analysis goal of predicting whether a text expresses positive or negative sentiment; instead, we aim to classify the Internet meme as a positive, negative, or neutral, identify the type of humor expressed and quantify the extent to which a particular effect is being expressed. Our system has been developed using CNN and LSTM and outperformed the baseline score.
gundapusunil at SemEval-2020 Task 9: Syntactic Semantic LSTM Architecture for SENTIment Analysis of Code-MIXed Data
Oct 09, 2020
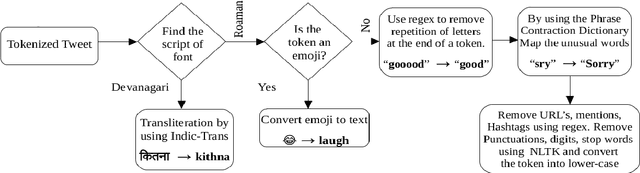
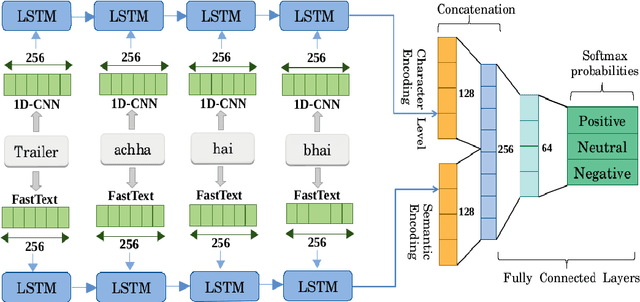
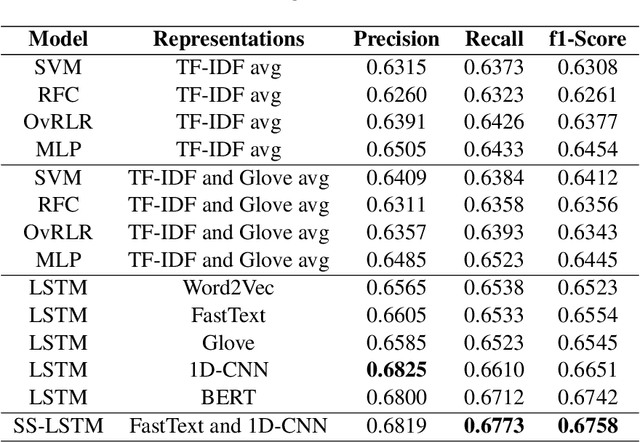
The phenomenon of mixing the vocabulary and syntax of multiple languages within the same utterance is called Code-Mixing. This is more evident in multilingual societies. In this paper, we have developed a system for SemEval 2020: Task 9 on Sentiment Analysis for Code-Mixed Social Media Text. Our system first generates two types of embeddings for the social media text. In those, the first one is character level embeddings to encode the character level information and to handle the out-of-vocabulary entries and the second one is FastText word embeddings for capturing morphology and semantics. These two embeddings were passed to the LSTM network and the system outperformed the baseline model.