Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edgegundapusunil at SemEval-2020 Task 9: Syntactic Semantic LSTM Architecture for SENTIment Analysis of Code-MIXed Data
Paper and Code

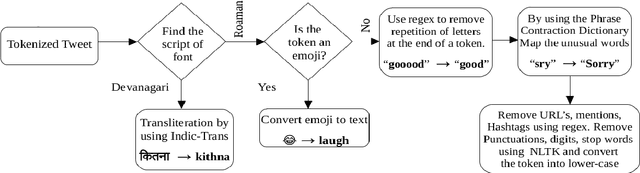
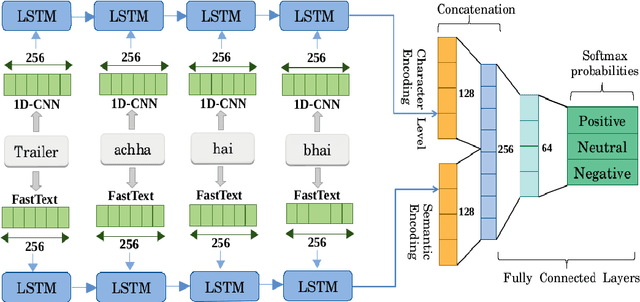
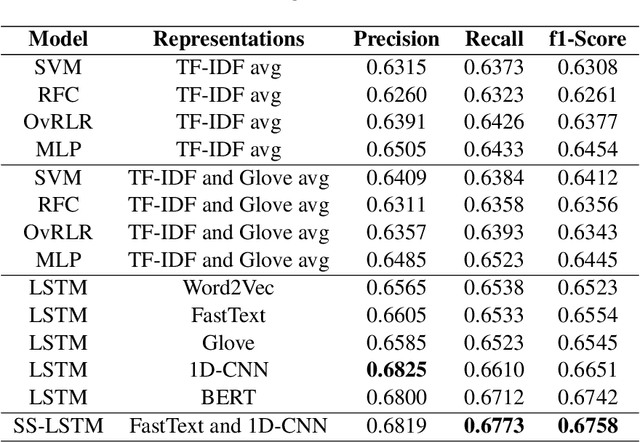
The phenomenon of mixing the vocabulary and syntax of multiple languages within the same utterance is called Code-Mixing. This is more evident in multilingual societies. In this paper, we have developed a system for SemEval 2020: Task 9 on Sentiment Analysis for Code-Mixed Social Media Text. Our system first generates two types of embeddings for the social media text. In those, the first one is character level embeddings to encode the character level information and to handle the out-of-vocabulary entries and the second one is FastText word embeddings for capturing morphology and semantics. These two embeddings were passed to the LSTM network and the system outperformed the baseline model.
* 6 pages, 2 figures
View paper on