 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMultichannel LSTM-CNN for Telugu Technical Domain Identification
Paper and Code
Feb 24, 2021
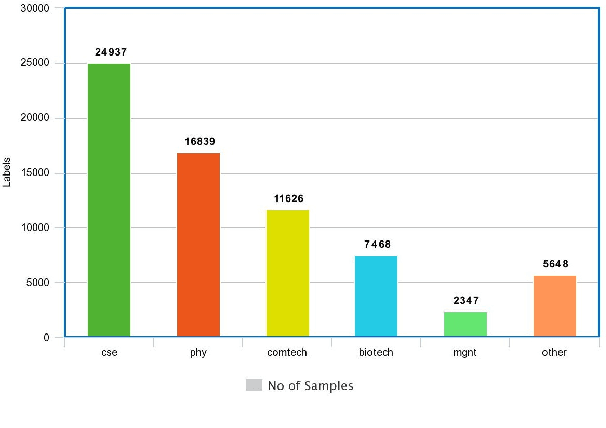
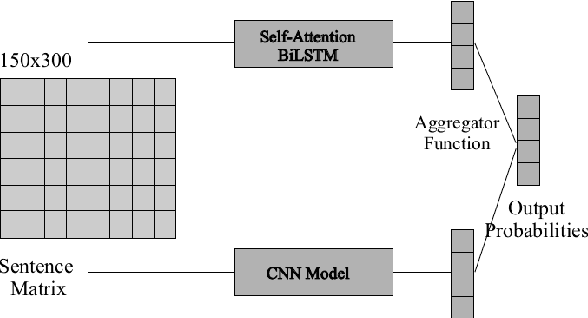

With the instantaneous growth of text information, retrieving domain-oriented information from the text data has a broad range of applications in Information Retrieval and Natural language Processing. Thematic keywords give a compressed representation of the text. Usually, Domain Identification plays a significant role in Machine Translation, Text Summarization, Question Answering, Information Extraction, and Sentiment Analysis. In this paper, we proposed the Multichannel LSTM-CNN methodology for Technical Domain Identification for Telugu. This architecture was used and evaluated in the context of the ICON shared task TechDOfication 2020 (task h), and our system got 69.9% of the F1 score on the test dataset and 90.01% on the validation set.