 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFederated Learning with Diffusion Models for Privacy-Sensitive Vision Tasks
Nov 28, 2023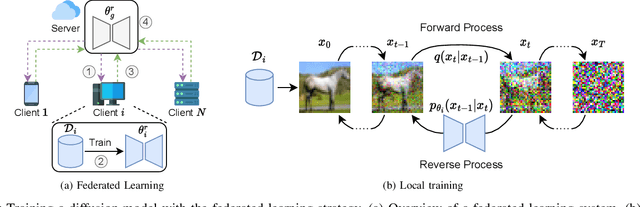


Diffusion models have shown great potential for vision-related tasks, particularly for image generation. However, their training is typically conducted in a centralized manner, relying on data collected from publicly available sources. This approach may not be feasible or practical in many domains, such as the medical field, which involves privacy concerns over data collection. Despite the challenges associated with privacy-sensitive data, such domains could still benefit from valuable vision services provided by diffusion models. Federated learning (FL) plays a crucial role in enabling decentralized model training without compromising data privacy. Instead of collecting data, an FL system gathers model parameters, effectively safeguarding the private data of different parties involved. This makes FL systems vital for managing decentralized learning tasks, especially in scenarios where privacy-sensitive data is distributed across a network of clients. Nonetheless, FL presents its own set of challenges due to its distributed nature and privacy-preserving properties. Therefore, in this study, we explore the FL strategy to train diffusion models, paving the way for the development of federated diffusion models. We conduct experiments on various FL scenarios, and our findings demonstrate that federated diffusion models have great potential to deliver vision services to privacy-sensitive domains.
Prototype Helps Federated Learning: Towards Faster Convergence
Mar 22, 2023
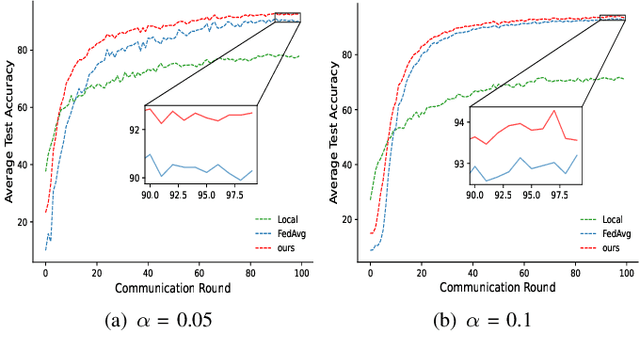
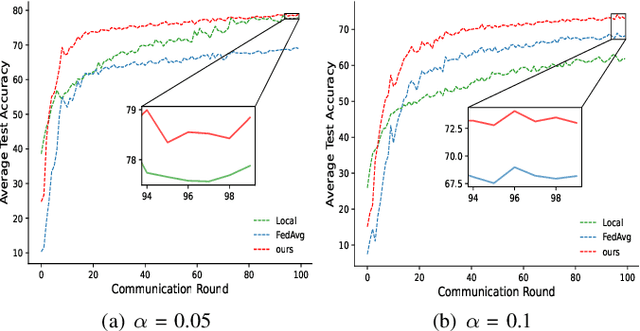
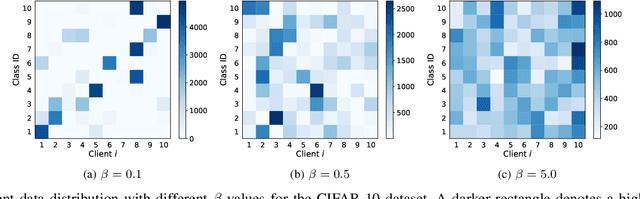
Federated learning (FL) is a distributed machine learning technique in which multiple clients cooperate to train a shared model without exchanging their raw data. However, heterogeneity of data distribution among clients usually leads to poor model inference. In this paper, a prototype-based federated learning framework is proposed, which can achieve better inference performance with only a few changes to the last global iteration of the typical federated learning process. In the last iteration, the server aggregates the prototypes transmitted from distributed clients and then sends them back to local clients for their respective model inferences. Experiments on two baseline datasets show that our proposal can achieve higher accuracy (at least 1%) and relatively efficient communication than two popular baselines under different heterogeneous settings.