 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAudited Reasoning Refinement: Fine-Tuning Language Models via LLM-Guided Step-Wise Evaluation and Correction
Sep 15, 2025



Training a task-specific small reasoning model is challenging when direct human supervision or high-quality labels are scarce. However, LLMs with reasoning capabilities produce abundant intermediate reasoning traces that can be systematically refined to create effective supervision signals. We propose Reason-Refine-then-Align (R2tA), which turns refined model rationales into supervision for training task-specific reasoning models. Our method generates initial reasoning and responses from an open-source base model on task-specific inputs, then refines these traces, fixing hallucinations and inconsistencies, to form a high-fidelity dataset. We perform a two-stage alignment, supervised fine-tuning (SFT), followed by direct preference optimization (DPO) to calibrate the model's intermediate reasoning with human-validated conceptual preferences and then condition the final output on that aligned reasoning. As a case study, we apply R2tA to evaluate extended entity relationship diagrams (EERDs) in database system design, a structurally complex task where prompt-only methods miss or hallucinate errors. We curated a dataset of 600 EERD variants (train/test split of 450/150, respectively) with induced mistakes spanning 11 categories. Empirical evaluation suggests R2tA provides a practical, cost-effective path to scalable LLM adaptation in data-scarce domains, enabling reproducible AI tools for education and beyond.
Steered Generation via Gradient Descent on Sparse Features
Feb 25, 2025Large language models (LLMs) encode a diverse range of linguistic features within their latent representations, which can be harnessed to steer their output toward specific target characteristics. In this paper, we modify the internal structure of LLMs by training sparse autoencoders to learn a sparse representation of the query embedding, allowing precise control over the model's attention distribution. We demonstrate that manipulating this sparse representation effectively transforms the output toward different stylistic and cognitive targets. Specifically, in an educational setting, we show that the cognitive complexity of LLM-generated feedback can be systematically adjusted by modifying the encoded query representation at a specific layer. To achieve this, we guide the learned sparse embedding toward the representation of samples from the desired cognitive complexity level, using gradient-based optimization in the latent space.
Sample Efficient Multimodal Semantic Augmentation for Incremental Summarization
Mar 08, 2023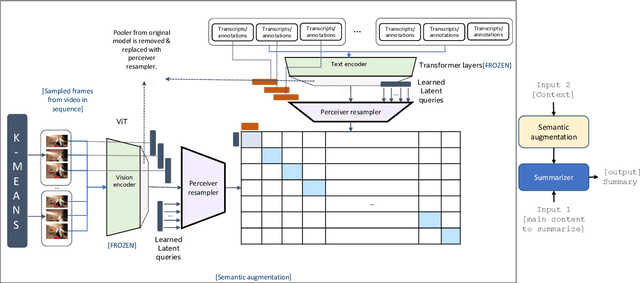
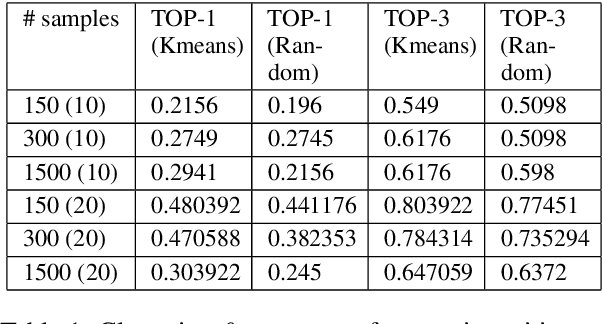

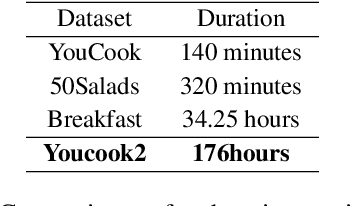
In this work, we develop a prompting approach for incremental summarization of task videos. We develop a sample-efficient few-shot approach for extracting semantic concepts as an intermediate step. We leverage an existing model for extracting the concepts from the images and extend it to videos and introduce a clustering and querying approach for sample efficiency, motivated by the recent advances in perceiver-based architectures. Our work provides further evidence that an approach with richer input context with relevant entities and actions from the videos and using these as prompts could enhance the summaries generated by the model. We show the results on a relevant dataset and discuss possible directions for the work.