Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSample Efficient Multimodal Semantic Augmentation for Incremental Summarization
Paper and Code
Mar 08, 2023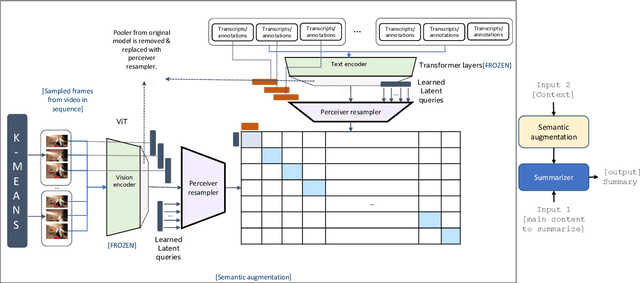
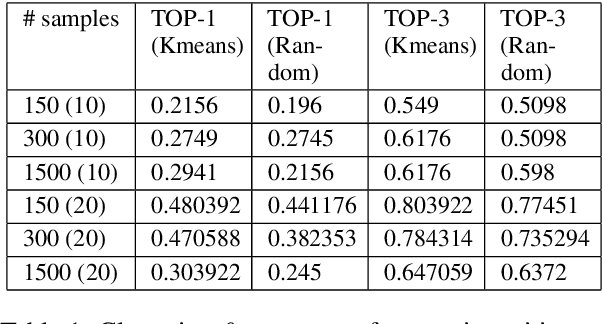

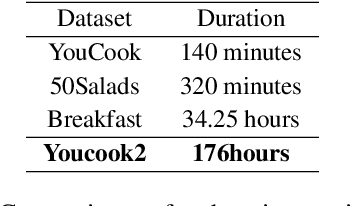
In this work, we develop a prompting approach for incremental summarization of task videos. We develop a sample-efficient few-shot approach for extracting semantic concepts as an intermediate step. We leverage an existing model for extracting the concepts from the images and extend it to videos and introduce a clustering and querying approach for sample efficiency, motivated by the recent advances in perceiver-based architectures. Our work provides further evidence that an approach with richer input context with relevant entities and actions from the videos and using these as prompts could enhance the summaries generated by the model. We show the results on a relevant dataset and discuss possible directions for the work.
View paper on