 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhy Do Neural Response Generation Models Prefer Universal Replies?
Aug 28, 2018
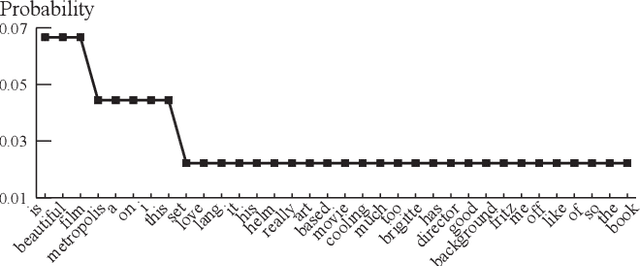

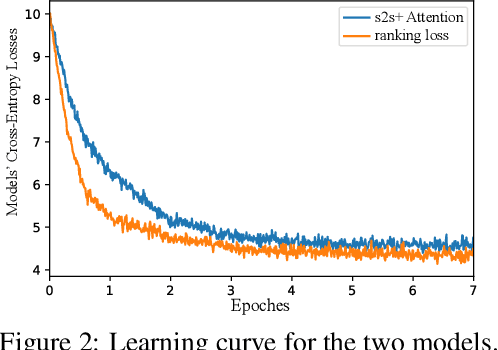
Recent advances in sequence-to-sequence learning reveal a purely data-driven approach to the response generation task. Despite its diverse applications, existing neural models are prone to producing short and generic replies, making it infeasible to tackle open-domain challenges. In this research, we analyze this critical issue in light of the model's optimization goal and the specific characteristics of the human-to-human dialog corpus. By decomposing the black box into parts, a detailed analysis of the probability limit was conducted to reveal the reason behind these universal replies. Based on these analyses, we propose a max-margin ranking regularization term to avoid the models leaning to these replies. Finally, empirical experiments on case studies and benchmarks with several metrics validate this approach.