 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBlock Format Error Bounds and Optimal Block Size Selection
Oct 11, 2022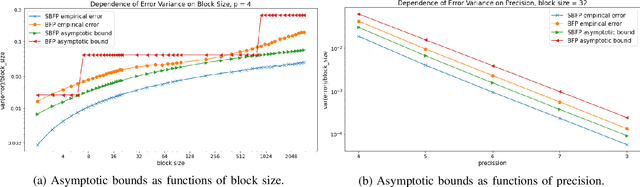
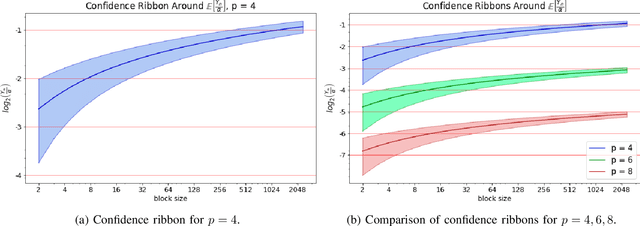
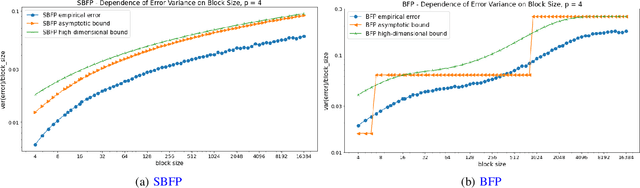
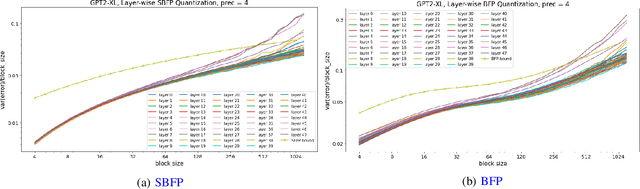
The amounts of data that need to be transmitted, processed, and stored by the modern deep neural networks have reached truly enormous volumes in the last few years calling for the invention of new paradigms both in hardware and software development. One of the most promising and rapidly advancing frontiers here is the creation of new data formats. In this work we focus on the family of block floating point numerical formats due to their combination of wide dynamic range, numerical accuracy, and efficient hardware implementation of inner products using simple integer arithmetic. These formats are characterized by a block of mantissas with a shared scale factor. The basic Block Floating Point (BFP) format quantizes the block scales into the nearest powers of two on the right. Its simple modification - Scaled BFP (SBFP) - stores the same scales in full precision and thus allows higher accuracy. In this paper, we study the statistical behavior of both these formats rigorously. We develop asymptotic bounds on the inner product error in SBFP- and BFP-quantized normally distributed vectors. Next, we refine those asymptotic results to finite dimensional settings and derive high-dimensional tight bounds for the same errors. Based on the obtained results we introduce a performance metric assessing accuracy of any block format. This metric allows us to determine the optimal parameters, such as the block size, yielding highest accuracy. In particular, we show that if the precision of the BFP format is fixed at 4 bits, the optimal block size becomes 64. All theoretical derivations are supported by numerical experiments and studies on the weights of publicly available pretrained neural networks.