 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFastLoop: Parallel Loop Closing with GPU-Acceleration in Visual SLAM
Mar 17, 2026Visual SLAM systems combine visual tracking with global loop closure to maintain a consistent map and accurate localization. Loop closure is a computationally expensive process as we need to search across the whole map for matches. This paper presents FastLoop, a GPU-accelerated loop closing module to alleviate this computational complexity. We identify key performance bottlenecks in the loop closing pipeline of visual SLAM and address them through parallel optimizations on the GPU. Specifically, we use task-level and data-level parallelism and integrate a GPU-accelerated pose graph optimization. Our implementation is built on top of ORB-SLAM3 and leverages CUDA for GPU programming. Experimental results show that FastLoop achieves an average speedup of 1.4x and 1.3x on the EuRoC dataset and 3.0x and 2.4x on the TUM-VI dataset for the loop closing module on desktop and embedded platforms, respectively, while maintaining the accuracy of the original system.
SLAM Adversarial Lab: An Extensible Framework for Visual SLAM Robustness Evaluation under Adverse Conditions
Mar 17, 2026We present SAL (SLAM Adversarial Lab), a modular framework for evaluating visual SLAM systems under adversarial conditions such as fog and rain. SAL represents each adversarial condition as a perturbation that transforms an existing dataset into an adversarial dataset. When transforming a dataset, SAL supports severity levels using easily-interpretable real-world units such as meters for fog visibility. SAL's extensible architecture decouples datasets, perturbations, and SLAM algorithms through common interfaces, so users can add new components without rewriting integration code. Moreover, SAL includes a search procedure that finds the severity level of a perturbation at which a SLAM system fails. To showcase the capabilities of SAL, our evaluation integrates seven SLAM algorithms and evaluates them across three datasets under weather, camera, and video transport perturbations.
Graphite: A GPU-Accelerated Mixed-Precision Graph Optimization Framework
Sep 30, 2025We present Graphite, a GPU-accelerated nonlinear graph optimization framework. It provides a CUDA C++ interface to enable the sharing of code between a realtime application, such as a SLAM system, and its optimization tasks. The framework supports techniques to reduce memory usage, including in-place optimization, support for multiple floating point types and mixed-precision modes, and dynamically computed Jacobians. We evaluate Graphite on well-known bundle adjustment problems and find that it achieves similar performance to MegBA, a solver specialized for bundle adjustment, while maintaining generality and using less memory. We also apply Graphite to global visual-inertial bundle adjustment on maps generated from stereo-inertial SLAM datasets, and observe speed ups of up to 59x compared to a CPU baseline. Our results indicate that our solver enables faster large-scale optimization on both desktop and resource-constrained devices.
A Study of Vulnerability Repair in JavaScript Programs with Large Language Models
Mar 19, 2024In recent years, JavaScript has become the most widely used programming language, especially in web development. However, writing secure JavaScript code is not trivial, and programmers often make mistakes that lead to security vulnerabilities in web applications. Large Language Models (LLMs) have demonstrated substantial advancements across multiple domains, and their evolving capabilities indicate their potential for automatic code generation based on a required specification, including automatic bug fixing. In this study, we explore the accuracy of LLMs, namely ChatGPT and Bard, in finding and fixing security vulnerabilities in JavaScript programs. We also investigate the impact of context in a prompt on directing LLMs to produce a correct patch of vulnerable JavaScript code. Our experiments on real-world software vulnerabilities show that while LLMs are promising in automatic program repair of JavaScript code, achieving a correct bug fix often requires an appropriate amount of context in the prompt.
Explore, Select, Derive, and Recall: Augmenting LLM with Human-like Memory for Mobile Task Automation
Dec 04, 2023


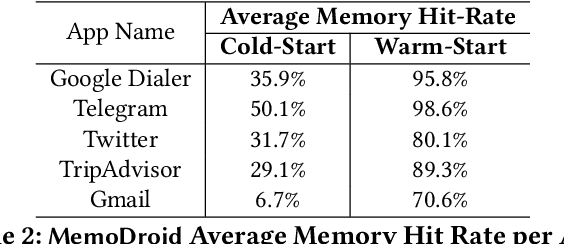
The advent of large language models (LLMs) has opened up new opportunities in the field of mobile task automation. Their superior language understanding and reasoning capabilities allow users to automate complex and repetitive tasks. However, due to the inherent unreliability and high operational cost of LLMs, their practical applicability is quite limited. To address these issues, this paper introduces MemoDroid, an innovative LLM-based mobile task automator enhanced with a unique app memory. MemoDroid emulates the cognitive process of humans interacting with a mobile app -- explore, select, derive, and recall. This approach allows for a more precise and efficient learning of a task's procedure by breaking it down into smaller, modular components that can be re-used, re-arranged, and adapted for various objectives. We implement MemoDroid using online LLMs services (GPT-3.5 and GPT-4) and evaluate its performance on 50 unique mobile tasks across 5 widely used mobile apps. The results indicate that MemoDroid can adapt learned tasks to varying contexts with 100% accuracy and reduces their latency and cost by 69.22% and 77.36% compared to a GPT-4 powered baseline.