 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient Rehearsal for Continual Learning in ASR via Singular Value Tuning
Jan 26, 2026Continual Learning (CL) in Automatic Speech Recognition (ASR) suffers from catastrophic forgetting when adapting to new tasks, domains, or speakers. A common strategy to mitigate this is to store a subset of past data in memory for rehearsal. However, rehearsal-based methods face key limitations: storing data is often costly, infeasible with pre-trained models, or restricted by privacy regulations. Running existing rehearsal-based methods with smaller memory sizes to alleviate these issues usually leads to degraded performance. We propose a rehearsal-based CL method that remains effective even with minimal memory. It operates in two stages: first, fine-tuning on the new task; second, applying Singular Value Decomposition (SVD) to the changes in linear layers and, in a parameter-efficient manner, retraining only gating vectors on the singular values, which control to extent to which updates from the first stage are accepted, using rehearsal. We extensively test and analyze our method on two monolingual and two multilingual benchmarks. Our method reduces forgetting and outperforms state-of-the-art CL approaches for ASR, even when limited to a single utterance per previous task.
Inverse-Hessian Regularization for Continual Learning in ASR
Jan 21, 2026Catastrophic forgetting remains a major challenge for continual learning (CL) in automatic speech recognition (ASR), where models must adapt to new domains without losing performance on previously learned conditions. Several CL methods have been proposed for ASR, and, recently, weight averaging - where models are averaged in a merging step after fine-tuning - has proven effective as a simple memory-free strategy. However, it is heuristic in nature and ignores the underlying loss landscapes of the tasks, hindering adaptability. In this work, we propose Inverse Hessian Regularization (IHR), a memory-free approach for CL in ASR that incorporates curvature information into the merging step. After fine-tuning on a new task, the adaptation is adjusted through a Kronecker-factored inverse Hessian approximation of the previous task, ensuring that the model moves primarily in directions less harmful to past performance, while keeping the method lightweight. We evaluate IHR on two CL benchmarks and show that it significantly outperforms state-of-the-art baselines, reducing forgetting while improving adaptability. Ablation studies and analyses further confirm its effectiveness.
Continual Learning With Quasi-Newton Methods
Mar 25, 2025Catastrophic forgetting remains a major challenge when neural networks learn tasks sequentially. Elastic Weight Consolidation (EWC) attempts to address this problem by introducing a Bayesian-inspired regularization loss to preserve knowledge of previously learned tasks. However, EWC relies on a Laplace approximation where the Hessian is simplified to the diagonal of the Fisher information matrix, assuming uncorrelated model parameters. This overly simplistic assumption often leads to poor Hessian estimates, limiting its effectiveness. To overcome this limitation, we introduce Continual Learning with Sampled Quasi-Newton (CSQN), which leverages Quasi-Newton methods to compute more accurate Hessian approximations. CSQN captures parameter interactions beyond the diagonal without requiring architecture-specific modifications, making it applicable across diverse tasks and architectures. Experimental results across four benchmarks demonstrate that CSQN consistently outperforms EWC and other state-of-the-art baselines, including rehearsal-based methods. CSQN reduces EWC's forgetting by 50 percent and improves its performance by 8 percent on average. Notably, CSQN achieves superior results on three out of four benchmarks, including the most challenging scenarios, highlighting its potential as a robust solution for continual learning.
* Published in IEEE Access
Unsupervised Online Continual Learning for Automatic Speech Recognition
Jun 18, 2024Adapting Automatic Speech Recognition (ASR) models to new domains leads to Catastrophic Forgetting (CF) of previously learned information. This paper addresses CF in the challenging context of Online Continual Learning (OCL), with tasks presented as a continuous data stream with unknown boundaries. We extend OCL for ASR into the unsupervised realm, by leveraging self-training (ST) to facilitate unsupervised adaptation, enabling models to adapt continually without label dependency and without forgetting previous knowledge. Through comparative analysis of various OCL and ST methods across two domain adaptation experiments, we show that UOCL suffers from significantly less forgetting compared to supervised OCL, allowing UOCL methods to approach the performance levels of supervised OCL. Our proposed UOCL extensions further boosts UOCL's efficacy. Our findings represent a significant step towards continually adaptable ASR systems, capable of leveraging unlabeled data across diverse domains.
Rehearsal-Free Online Continual Learning for Automatic Speech Recognition
Jun 19, 2023

Fine-tuning an Automatic Speech Recognition (ASR) model to new domains results in degradation on original domains, referred to as Catastrophic Forgetting (CF). Continual Learning (CL) attempts to train ASR models without suffering from CF. While in ASR, offline CL is usually considered, online CL is a more realistic but also more challenging scenario where the model, unlike in offline CL, does not know when a task boundary occurs. Rehearsal-based methods, which store previously seen utterances in a memory, are often considered for online CL, in ASR and other research domains. However, recent research has shown that weight averaging is an effective method for offline CL in ASR. Based on this result, we propose, in this paper, a rehearsal-free method applicable for online CL. Our method outperforms all baselines, including rehearsal-based methods, in two experiments. Our method is a next step towards general CL for ASR, which should enable CL in all scenarios with few if any constraints.
Weight Averaging: A Simple Yet Effective Method to Overcome Catastrophic Forgetting in Automatic Speech Recognition
Oct 27, 2022

Adapting a trained Automatic Speech Recognition (ASR) model to new tasks results in catastrophic forgetting of old tasks, limiting the model's ability to learn continually and to be extended to new speakers, dialects, languages, etc. Focusing on End-to-End ASR, in this paper, we propose a simple yet effective method to overcome catastrophic forgetting: weight averaging. By simply taking the average of the previous and the adapted model, our method achieves high performance on both the old and new tasks. It can be further improved by introducing a knowledge distillation loss during the adaptation. We illustrate the effectiveness of our method on both monolingual and multilingual ASR. In both cases, our method strongly outperforms all baselines, even in its simplest form.
Using Adapters to Overcome Catastrophic Forgetting in End-to-End Automatic Speech Recognition
Mar 30, 2022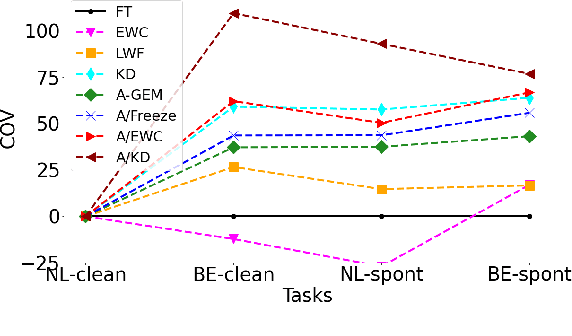
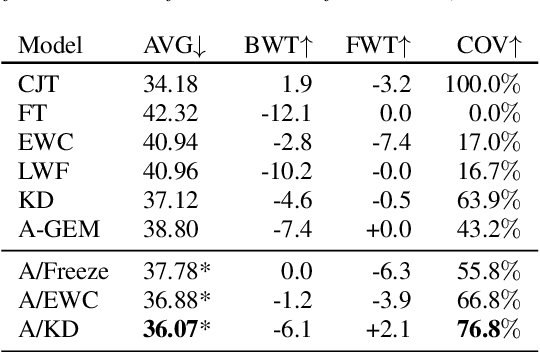

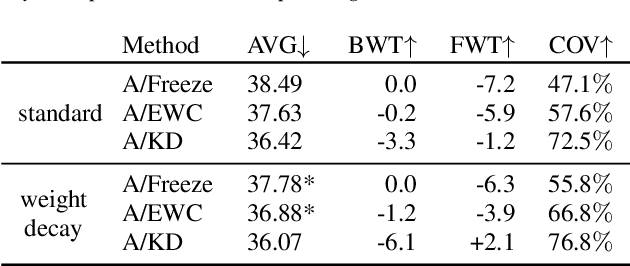
Learning a set of tasks in sequence remains a challenge for Artificial Neural Networks, which, in such scenarios, tend to suffer from Catastrophic Forgetting (CF). The same applies to End-to-End (E2E) Automatic Speech Recognition (ASR) models, even for monolingual tasks. In this paper, we aim to overcome CF for E2E ASR by inserting adapters, small architectures of few parameters which allow a general model to be fine-tuned to a specific task, into our model. We make these adapters task-specific, while either freezing or regularizing the parameters of the model shared by all tasks, thus stimulating the model to fully exploit the adapter parameters while keeping the shared parameters such that they work well for all tasks. Our best method is able to close the gap between worst case (naively fine-tuning) and best case (jointly training on all tasks) by more than 75% after a set of four monolingual tasks.
Continual Learning for Monolingual End-to-End Automatic Speech Recognition
Dec 17, 2021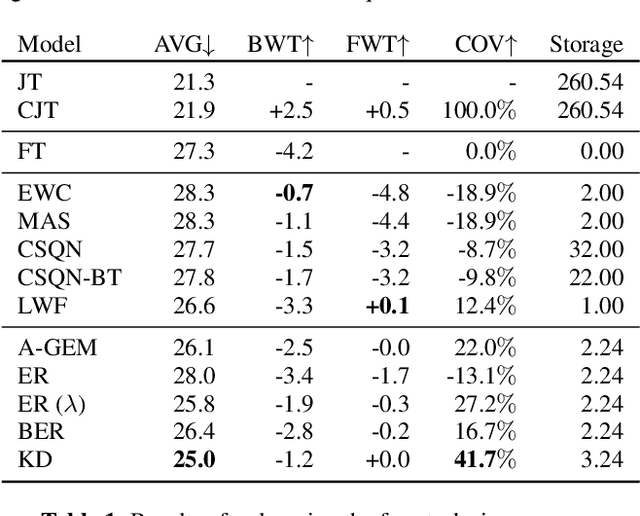
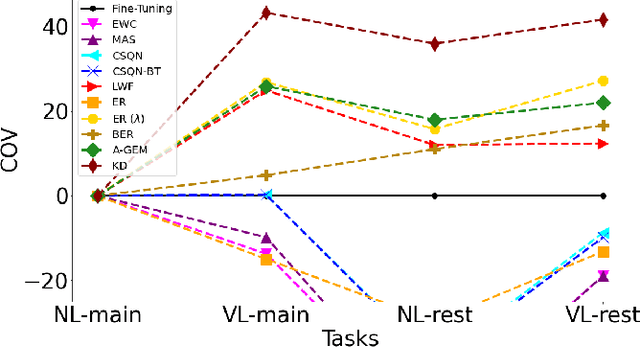
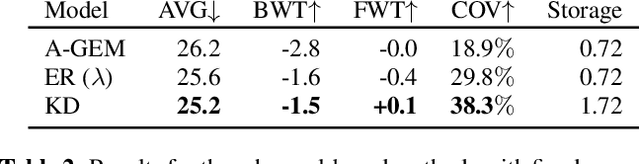
Adapting Automatic Speech Recognition (ASR) models to new domains leads to a deterioration of performance on the original domain(s), a phenomenon called Catastrophic Forgetting (CF). Even monolingual ASR models cannot be extended to new accents, dialects, topics, etc. without suffering from CF, making them unable to be continually enhanced without storing all past data. Fortunately, Continual Learning (CL) methods, which aim to enable continual adaptation while overcoming CF, can be used. In this paper, we implement an extensive number of CL methods for End-to-End ASR and test and compare their ability to extend a monolingual Hybrid CTC-Transformer model across four new tasks. We find that the best performing CL method closes the gap between the fine-tuned model (lower bound) and the model trained jointly on all tasks (upper bound) by more than 40%, while requiring access to only 0.6% of the original data.