 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePredicting fixed-sample test decisions enables anytime-valid inference
Feb 14, 2026Statistical hypothesis tests typically use prespecified sample sizes, yet data often arrive sequentially. Interim analyses invalidate classical error guarantees, while existing sequential methods require rigid testing preschedules or incur substantial losses in statistical power. We introduce a simple procedure that transforms any fixed-sample hypothesis test into an anytime-valid test while ensuring Type-I error control and near-optimal power with substantial sample savings when the null hypothesis is false. At each step, the procedure predicts the probability that a classical test would reject the null hypothesis at its fixed-sample size, treating future observations as missing data under the null hypothesis. Thresholding this probability yields an anytime-valid stopping rule. In areas such as clinical trials, stopping early and safely can ensure that subjects receive the best treatments and accelerate the development of effective therapies.
General Bayesian Updating and the Loss-Likelihood Bootstrap
May 22, 2018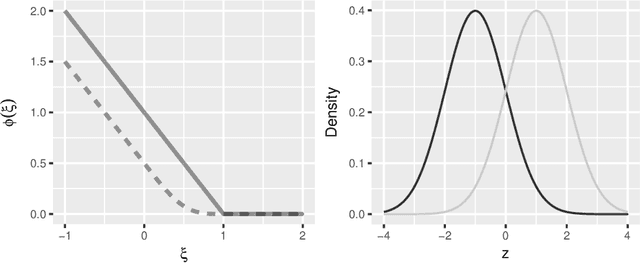
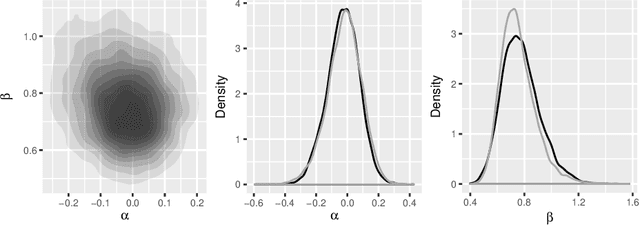

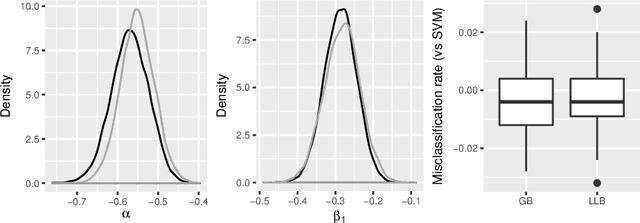
In this paper we revisit the weighted likelihood bootstrap, a method that generates samples from an approximate Bayesian posterior of a parametric model. We show that the same method can be derived, without approximation, under a Bayesian nonparametric model with the parameter of interest defined as minimising an expected negative log-likelihood under an unknown sampling distribution. This interpretation enables us to extend the weighted likelihood bootstrap to posterior sampling for parameters minimizing an expected loss. We call this method the loss-likelihood bootstrap. We make a connection between this and general Bayesian updating, which is a way of updating prior belief distributions without needing to construct a global probability model, yet requires the calibration of two forms of loss function. The loss-likelihood bootstrap is used to calibrate the general Bayesian posterior by matching asymptotic Fisher information. We demonstrate the methodology on a number of examples.