 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePlanning with Partially Observable Markov Decision Processes: Advances in Exact Solution Method
Jan 30, 2013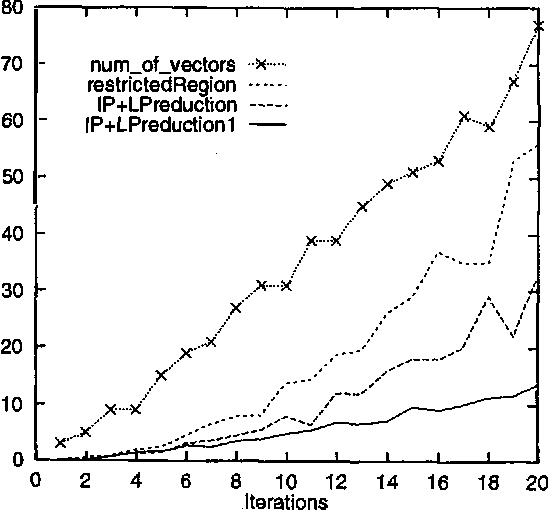
There is much interest in using partially observable Markov decision processes (POMDPs) as a formal model for planning in stochastic domains. This paper is concerned with finding optimal policies for POMDPs. We propose several improvements to incremental pruning, presently the most efficient exact algorithm for solving POMDPs.
A Method for Speeding Up Value Iteration in Partially Observable Markov Decision Processes
Jan 23, 2013We present a technique for speeding up the convergence of value iteration for partially observable Markov decisions processes (POMDPs). The underlying idea is similar to that behind modified policy iteration for fully observable Markov decision processes (MDPs). The technique can be easily incorporated into any existing POMDP value iteration algorithms. Experiments have been conducted on several test problems with one POMDP value iteration algorithm called incremental pruning. We find that the technique can make incremental pruning run several orders of magnitude faster.