Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePlanning with Partially Observable Markov Decision Processes: Advances in Exact Solution Method
Paper and Code
Jan 30, 2013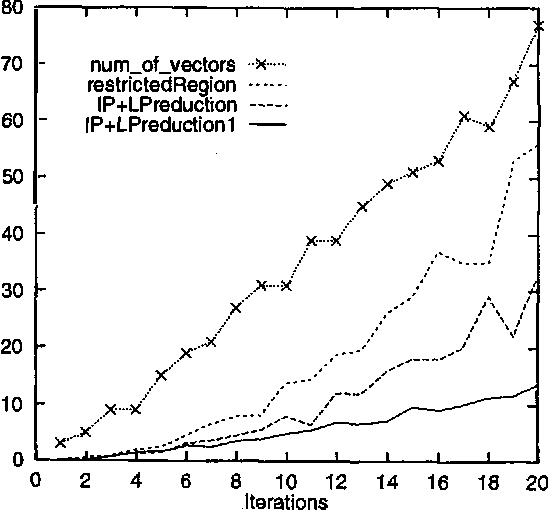
There is much interest in using partially observable Markov decision processes (POMDPs) as a formal model for planning in stochastic domains. This paper is concerned with finding optimal policies for POMDPs. We propose several improvements to incremental pruning, presently the most efficient exact algorithm for solving POMDPs.
* Appears in Proceedings of the Fourteenth Conference on Uncertainty in
Artificial Intelligence (UAI1998)
View paper on