 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLarge Language Models for Automatic Detection of Sensitive Topics
Sep 02, 2024
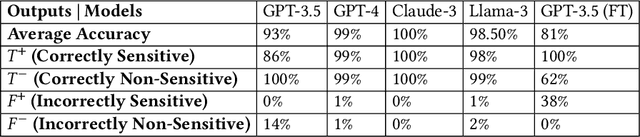

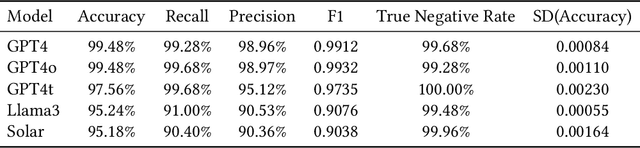
Sensitive information detection is crucial in content moderation to maintain safe online communities. Assisting in this traditionally manual process could relieve human moderators from overwhelming and tedious tasks, allowing them to focus solely on flagged content that may pose potential risks. Rapidly advancing large language models (LLMs) are known for their capability to understand and process natural language and so present a potential solution to support this process. This study explores the capabilities of five LLMs for detecting sensitive messages in the mental well-being domain within two online datasets and assesses their performance in terms of accuracy, precision, recall, F1 scores, and consistency. Our findings indicate that LLMs have the potential to be integrated into the moderation workflow as a convenient and precise detection tool. The best-performing model, GPT-4o, achieved an average accuracy of 99.5\% and an F1-score of 0.99. We discuss the advantages and potential challenges of using LLMs in the moderation workflow and suggest that future research should address the ethical considerations of utilising this technology.