 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFlexible Robust Beamforming for Multibeam Satellite Downlink using Reinforcement Learning
Feb 26, 2024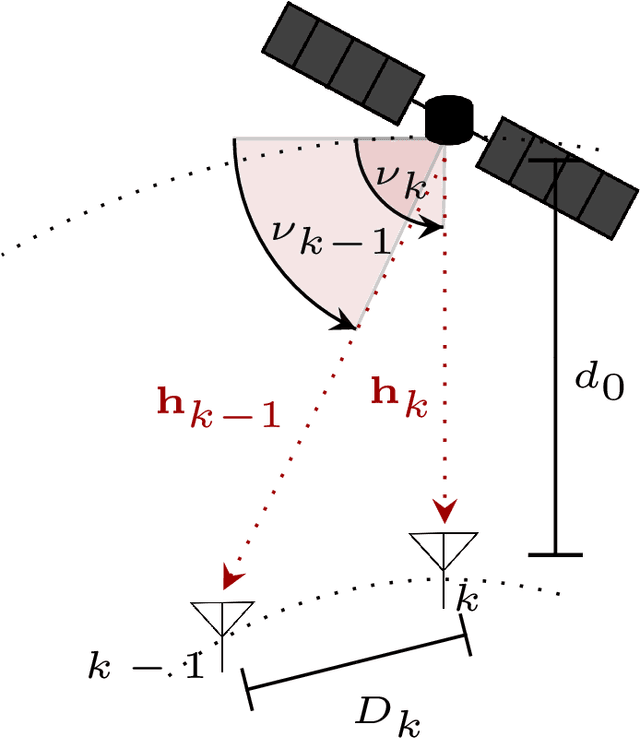



Low Earth Orbit (LEO) satellite-to-handheld connections herald a new era in satellite communications. Space-Division Multiple Access (SDMA) precoding is a method that mitigates interference among satellite beams, boosting spectral efficiency. While optimal SDMA precoding solutions have been proposed for ideal channel knowledge in various scenarios, addressing robust precoding with imperfect channel information has primarily been limited to simplified models. However, these models might not capture the complexity of LEO satellite applications. We use the Soft Actor-Critic (SAC) deep Reinforcement Learning (RL) method to learn robust precoding strategies without the need for explicit insights into the system conditions and imperfections. Our results show flexibility to adapt to arbitrary system configurations while performing strongly in terms of achievable rate and robustness to disruptive influences compared to analytical benchmark precoders.
A Multi-Task Approach to Robust Deep Reinforcement Learning for Resource Allocation
Apr 25, 2023With increasing complexity of modern communication systems, machine learning algorithms have become a focal point of research. However, performance demands have tightened in parallel to complexity. For some of the key applications targeted by future wireless, such as the medical field, strict and reliable performance guarantees are essential, but vanilla machine learning methods have been shown to struggle with these types of requirements. Therefore, the question is raised whether these methods can be extended to better deal with the demands imposed by such applications. In this paper, we look at a combinatorial resource allocation challenge with rare, significant events which must be handled properly. We propose to treat this as a multi-task learning problem, select two methods from this domain, Elastic Weight Consolidation and Gradient Episodic Memory, and integrate them into a vanilla actor-critic scheduler. We compare their performance in dealing with Black Swan Events with the state-of-the-art of augmenting the training data distribution and report that the multi-task approach proves highly effective.
On the Importance of Exploration for Real Life Learned Algorithms
Apr 21, 2023The quality of data driven learning algorithms scales significantly with the quality of data available. One of the most straight-forward ways to generate good data is to sample or explore the data source intelligently. Smart sampling can reduce the cost of gaining samples, reduce computation cost in learning, and enable the learning algorithm to adapt to unforeseen events. In this paper, we teach three Deep Q-Networks (DQN) with different exploration strategies to solve a problem of puncturing ongoing transmissions for URLLC messages. We demonstrate the efficiency of two adaptive exploration candidates, variance-based and Maximum Entropy-based exploration, compared to the standard, simple epsilon-greedy exploration approach.
Robust Deep Reinforcement Learning Scheduling via Weight Anchoring
Apr 20, 2023Questions remain on the robustness of data-driven learning methods when crossing the gap from simulation to reality. We utilize weight anchoring, a method known from continual learning, to cultivate and fixate desired behavior in Neural Networks. Weight anchoring may be used to find a solution to a learning problem that is nearby the solution of another learning problem. Thereby, learning can be carried out in optimal environments without neglecting or unlearning desired behavior. We demonstrate this approach on the example of learning mixed QoS-efficient discrete resource scheduling with infrequent priority messages. Results show that this method provides performance comparable to the state of the art of augmenting a simulation environment, alongside significantly increased robustness and steerability.
Learning Resource Scheduling with High Priority Users using Deep Deterministic Policy Gradients
Apr 19, 2023Advances in mobile communication capabilities open the door for closer integration of pre-hospital and in-hospital care processes. For example, medical specialists can be enabled to guide on-site paramedics and can, in turn, be supplied with live vitals or visuals. Consolidating such performance-critical applications with the highly complex workings of mobile communications requires solutions both reliable and efficient, yet easy to integrate with existing systems. This paper explores the application of Deep Deterministic Policy Gradient~(\ddpg) methods for learning a communications resource scheduling algorithm with special regards to priority users. Unlike the popular Deep-Q-Network methods, the \ddpg is able to produce continuous-valued output. With light post-processing, the resulting scheduler is able to achieve high performance on a flexible sum-utility goal.
Learning Model-Free Robust Precoding for Cooperative Multibeam Satellite Communications
Mar 13, 2023


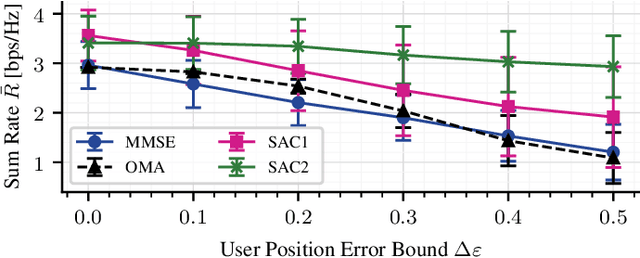
Direct Low Earth Orbit satellite-to-handheld links are expected to be part of a new era in satellite communications. Space-Division Multiple Access precoding is a technique that reduces interference among satellite beams, therefore increasing spectral efficiency by allowing cooperating satellites to reuse frequency. Over the past decades, optimal precoding solutions with perfect channel state information have been proposed for several scenarios, whereas robust precoding with only imperfect channel state information has been mostly studied for simplified models. In particular, for Low Earth Orbit satellite applications such simplified models might not be accurate. In this paper, we use the function approximation capabilities of the Soft Actor-Critic deep Reinforcement Learning algorithm to learn robust precoding with no knowledge of the system imperfections.
Deep Reinforcement Model Selection for Communications Resource Allocation in On-Site Medical Care
Nov 12, 2021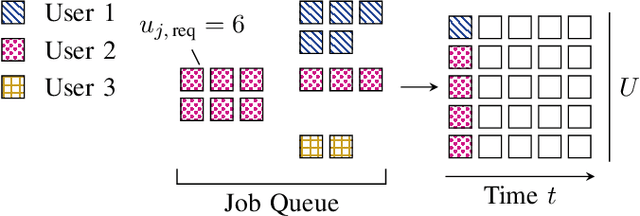

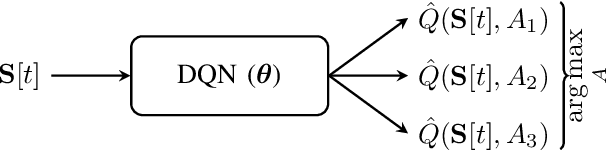

Greater capabilities of mobile communications technology enable interconnection of on-site medical care at a scale previously unavailable. However, embedding such critical, demanding tasks into the already complex infrastructure of mobile communications proves challenging. This paper explores a resource allocation scenario where a scheduler must balance mixed performance metrics among connected users. To fulfill this resource allocation task, we present a scheduler that adaptively switches between different model-based scheduling algorithms. We make use of a deep Q-Network to learn the benefit of selecting a scheduling paradigm for a given situation, combining advantages from model-driven and data-driven approaches. The resulting ensemble scheduler is able to combine its constituent algorithms to maximize a sum-utility cost function while ensuring performance on designated high-priority users.